.png)
Deep Reinforcement Learning - Asynchronous Advantage Actor-Critic (A3C)
Reinforcement Learning (RL) is a powerful technique for training agents to make decisions in complex environments. Asynchronous Advantage Actor-Critic (A3C) is one of the most popular RL algorithms, known for its efficiency, stability, and ability to learn in parallel environments.
This guide provides a detailed explanation of A3C, covering its working mechanism, advantages, implementation, and real-world applications.
1. Understanding Actor-Critic Methods
Before diving into A3C, let’s understand Actor-Critic (AC) methods, which form the foundation of A3C.
What is an Actor-Critic Method?
- Actor: Learns the optimal policy π(s)\pi(s), which decides which action to take in a given state.
- Critic: Estimates the value function V(s)V(s), which predicts how good a state is in terms of future rewards.
- The Actor updates the policy based on feedback from the Critic.
Why Actor-Critic Instead of Value-Based Methods?
- Better for continuous action spaces (unlike DQN, which works well only for discrete actions).
- More stable training compared to pure policy-based methods like REINFORCE.
- Efficient use of collected experience, making it suitable for complex environments.
2. What is Asynchronous Advantage Actor-Critic (A3C)?
A3C is an improved Actor-Critic method that uses multiple parallel agents to explore different parts of the environment asynchronously.
Key Features of A3C:
✔ Asynchronous learning – multiple agents explore the environment simultaneously.
✔ Efficient in high-dimensional spaces – works well in complex environments (e.g., robotics, games).
✔ Uses Advantage Function – reduces variance in updates for better learning.
✔ No experience replay – makes training faster and more memory-efficient than DQN.
Main Idea of A3C:
Instead of using a single agent like DQN or PPO, A3C runs multiple agents in parallel.
- These agents collect experiences independently and update the global network asynchronously.
- This improves exploration and learning speed.
3. How A3C Works – Step by Step
A3C follows these steps:
Step 1: Create Multiple Parallel Agents
- Unlike single-agent RL (e.g., DQN), A3C runs multiple agents in separate environments.
- Each agent collects experiences independently.
Step 2: Compute the Advantage Function
- A3C uses the Advantage Function to reduce variance and improve training stability.
The Advantage function tells whether an action was better or worse than expected:
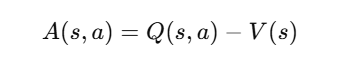
where:
- Q(s,a) is the action-value function.
- V(s) is the state-value function.
- Why use Advantage Function?
- Prevents high variance in policy updates.
- Helps the agent focus on improving important actions.
Step 3: Train Actor and Critic Together
- The Actor updates the policy using the Advantage Function.
The Critic updates the value function to improve predictions.
Loss functions used in A3C:
Actor Loss (Policy Gradient):
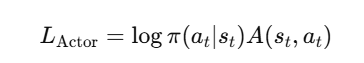
Critic Loss (Mean Squared Error for Value Function):
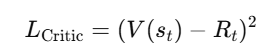
Entropy Loss (for exploration):
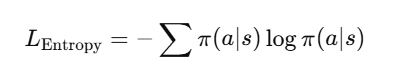
- This encourages exploration by preventing the policy from becoming too greedy too soon.
Why Train Actor and Critic Together in A3C/PPO?
In Actor-Critic methods (like A3C and PPO), we train both the Actor (policy network) and the Critic (value network) simultaneously to improve stability and efficiency. Here’s why:
| Aspect | Actor (Policy Network) | Critic (Value Network) | Why Train Together? |
|---|---|---|---|
| Purpose | Learns the optimal policy (π) to maximize rewards. | Learns to estimate the value function (V) for better decision-making. | The actor relies on the critic’s value estimates to improve. |
| Loss Function | Policy Gradient Loss | Mean Squared Error (MSE) | The actor’s updates depend on accurate critic predictions. |
| Role in Training | Decides which action to take based on state. | Evaluates how good the state is and provides feedback. | The critic guides the actor, preventing high variance in training. |
| Exploration | Encouraged via entropy loss (to avoid premature convergence). | Helps maintain stable learning by reducing variance. | The critic prevents the actor from making poor decisions based on high variance estimates. |
| Efficiency | Less efficient alone (high variance). | Can be slow in convergence alone. | Together, they balance exploration and exploitation for efficient learning. |
Key Benefits of Joint Training
✅ Stabilizes Training – The critic reduces variance in policy updates, leading to faster convergence.
✅ Improves Sample Efficiency – The actor efficiently learns from critic feedback, requiring fewer samples.
✅ Balances Exploration & Exploitation – Entropy loss prevents premature convergence, ensuring diverse strategies.
✅ Better Long-Term Decision-Making – The critic corrects suboptimal short-term choices, refining the policy gradually.
Step 4: Update the Global Network Asynchronously
- Each agent computes gradients and updates the global network.
- These updates do not wait for other agents, making learning more efficient.
Step 5: Repeat Until Convergence
- The process continues until the agent learns the optimal policy.
4. Why A3C Works Better Than Older Methods?
| Comparison | A3C (Asynchronous Advantage Actor-Critic) | DQN (Deep Q-Networks) | REINFORCE (Vanilla Policy Gradient) | A2C (Advantage Actor-Critic) |
|---|---|---|---|---|
| Experience Replay | ❌ Not needed (on-policy updates) | ✅ Uses replay buffer (off-policy) | ❌ No experience replay | ❌ No experience replay |
| Training Updates | ✅ Asynchronous (multiple agents update in parallel) | ❌ Sequential updates (single agent) | ❌ Single update per episode | ✅ Synchronous (waits for all agents before update) |
| Variance Reduction | ✅ Lower variance (uses Critic for value estimation) | ❌ Higher variance due to overestimation of Q-values | ❌ High variance (no Critic) | ✅ Lower variance (uses Critic) |
| Efficiency | ✅ More memory-efficient (no replay buffer) | ❌ Requires more memory for experience replay | ❌ Less efficient policy updates | ✅ More efficient than REINFORCE |
| Exploration | ✅ Better exploration due to asynchronous agents | ❌ Prone to local optima due to replay memory | ❌ No structured exploration | ✅ Decent exploration but less than A3C |
| Performance in Large State Spaces | ✅ Works well in complex environments | ❌ Struggles with large state spaces | ❌ Inefficient for large state spaces | ✅ Performs well but slower than A3C |
5. Implementing A3C in Python (Using Stable-Baselines3)
You can implement A3C using Stable-Baselines3.
Installation:
pip install stable-baselines3 gym
Training an Agent in OpenAI Gym (CartPole)
import gym
from stable_baselines3 import A2C
# Create the environment
env = gym.make("CartPole-v1")
# Initialize the A3C model (Stable-Baselines3 uses A2C instead of A3C)
model = A2C("MlpPolicy", env, verbose=1)
# Train the model
model.learn(total_timesteps=10000)
# Test the trained agent
obs = env.reset()
done = False
while not done:
action, _states = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
env.close()
🔹 Note:
- Stable-Baselines3 does not support A3C directly but A2C (synchronous version of A3C) works similarly.
- A3C is usually implemented using custom PyTorch or TensorFlow environments.
6. Applications of A3C
🔹 Gaming & AI Agents
- Used in Google’s DeepMind AI for Atari games.
- Applied in OpenAI’s AI for real-time strategy games.
🔹 Robotics & Automation
- Helps in robotic grasping and movement control.
- Used in autonomous drone navigation.
🔹 Finance & Algorithmic Trading
- Used in portfolio management and risk analysis.
- Helps in fraud detection by optimizing security decisions.
🔹 Healthcare & Medical Diagnosis
- Applied in personalized treatment planning.
- Helps in medical image analysis and pattern detection.
7. Self-Assessment Quiz
- What is the main advantage of A3C over DQN?
a) Uses experience replay
b) Learns faster using multiple agents
c) Only works with discrete action spaces
d) Uses a fixed learning rate - Why does A3C use entropy regularization?
a) To encourage exploration
b) To decrease training time
c) To improve Q-learning
d) To make the policy deterministic
8. Key Takeaways & Summary
✅ A3C is an Actor-Critic RL algorithm that uses multiple agents running in parallel.
✅ It updates the policy asynchronously, making training faster and more stable.
✅ A3C does not use experience replay, reducing memory usage.
✅ Works well in complex, high-dimensional environments like gaming, robotics, and finance.
✅ Compared to DQN and A2C, A3C learns faster and explores better.
Next Blog- Introduction to Popular AI Libraries TensorFlow






.jpg)














.jpg)


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)







































