.png)
Deep Reinforcement Learning (PPO)
Reinforcement Learning (RL) is a powerful technique for training agents to make optimal decisions in complex environments. One of the most widely used RL algorithms is Proximal Policy Optimization (PPO), developed by OpenAI.
PPO is widely used in applications such as robotics, gaming (e.g., Dota 2 AI), finance, and autonomous systems because of its stability, efficiency, and ease of implementation.
This guide provides a detailed explanation of PPO, covering everything from the intuition behind it to hands-on implementation.
1. Understanding Policy-Based Reinforcement Learning
Reinforcement learning algorithms are divided into two main categories:
- Value-Based Methods (e.g., Deep Q-Networks, DQN)
- These methods use a function to estimate the value of states or state-action pairs.
- Example: DQN learns an optimal Q-function that tells the agent the expected reward for taking an action in a given state.
- Policy-Based Methods (e.g., REINFORCE, A2C, PPO)
- These methods directly learn a policy that maps states to actions without estimating value functions.
- PPO belongs to this category.
💡 Key Advantage of Policy-Based Methods (Like PPO):
- Better for continuous action spaces (e.g., robotics, self-driving cars).
- More stable learning process than value-based methods.
2. What is Proximal Policy Optimization (PPO)?
PPO is a policy-based RL algorithm designed to improve training stability and performance.
Key Features of PPO:
✅ Improves upon older policy gradient methods (e.g., REINFORCE, A2C)
✅ Uses a clipped objective function to ensure gradual updates (avoiding drastic policy changes)
✅ Computationally efficient (compared to Trust Region Policy Optimization, TRPO)
✅ Performs well in high-dimensional, complex environments
💡 Main Idea of PPO:
Instead of making large updates to the policy, PPO constrains the updates to be small. This helps maintain a balance between exploration and exploitation while ensuring stability in learning.
3. How PPO Works – Step by Step
PPO follows these main steps:
Step 1: Collect Experiences
- The agent interacts with the environment using a policy πθ\pi_{\theta}.
- It collects states, actions, and rewards over multiple time steps.
- These experiences form a trajectory (sequence of experiences).
Step 2: Compute the Advantage Function
- PPO estimates how good an action was compared to the average action taken in a given state.
This is done using an Advantage Function:
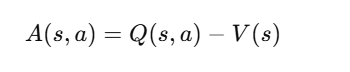
where:
- Q(s,a) is the action-value function (expected total reward after taking action aa in state ss).
- V(s) is the value function (expected total reward from state ss).
- A common approach is using Generalized Advantage Estimation (GAE) to smooth the advantage estimates.
Step 3: Compute the Probability Ratio
PPO compares the new policy with the old policy using a ratio:
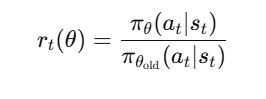
where:
- πθ is the new policy.
- πθold is the old policy.
- rt(θ) tells us how much the new policy has changed compared to the old one.
Step 4: Clip the Objective Function
Instead of making large, unstable updates, PPO limits how much the policy can change by clipping the probability ratio.
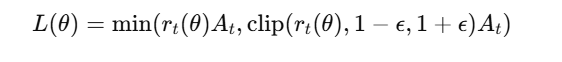
where:
- ϵ(epsilon) is a small number (e.g., 0.2) that controls the clipping range.
Why Clipping?
- Prevents large updates that make training unstable.
- Ensures the policy doesn’t change too drastically.
Step 5: Update the Policy
- The policy is updated only if the new policy improves performance within the clipped range.
- PPO optimizes this using gradient ascent.
Step 6: Repeat Until Convergence
- Steps 1 to 5 are repeated until the agent learns an optimal policy.
4. Why PPO Works Better Than Older Methods?
Here’s a tabular comparison of PPO vs. older methods:
| Comparison | PPO (Proximal Policy Optimization) | REINFORCE (Vanilla Policy Gradient) | A2C (Advantage Actor-Critic) | TRPO (Trust Region Policy Optimization) |
|---|---|---|---|---|
| Stability | More stable due to clipping | High variance, unstable updates | Higher variance | Very stable |
| Sample Efficiency | Uses experience efficiently | Less efficient | Less efficient | More efficient than A2C & REINFORCE |
| Training Steps per Batch | Multiple epochs | Single update per batch | Single update per batch | Single update per batch |
| Gradient Update Method | Clipping to prevent large updates | Unclipped, leading to instability | No clipping, higher variance | Trust region constraint (complex) |
| Implementation Complexity | Simple and easy to implement | Very simple, but unstable | Moderate complexity | Complex due to second-order optimization |
| Performance | High performance, widely used | Can be unstable & inefficient | Better than REINFORCE, but less efficient than PPO | Strong performance but harder to implement |
5. Implementing PPO in Python (Using Stable-Baselines3)
You can easily implement PPO using Stable-Baselines3 (a deep RL library).
Installation:
pip install stable-baselines3 gym
Training an Agent in OpenAI Gym (CartPole)
import gym
from stable_baselines3 import PPO
# Create the environment
env = gym.make("CartPole-v1")
# Initialize the PPO model
model = PPO("MlpPolicy", env, verbose=1)
# Train the model
model.learn(total_timesteps=10000)
# Test the trained agent
obs = env.reset()
done = False
while not done:
action, _states = model.predict(obs)
obs, reward, done, info = env.step(action)
env.render()
env.close()
6. Applications of PPO
🔹 Gaming & AI Agents
- Used in OpenAI Five (defeated human players in Dota 2).
- Applied in AlphaStar (trained to play StarCraft II).
🔹 Robotics & Automation
- Enables robotic arms to grasp objects and navigate autonomously.
- Used in self-driving cars to optimize lane changes.
🔹 Finance & Trading
- Used in algorithmic trading to optimize stock portfolios.
- Helps in fraud detection by learning optimal security patterns.
🔹 Healthcare
- Used in medical diagnosis AI models to optimize treatment plans.
7. Self-Assessment Quiz
- What is the main benefit of using clipping in PPO?
a) Increases exploration
b) Prevents drastic policy updates
c) Makes training faster
d) None of the above - Why is PPO more stable than REINFORCE?
a) Uses clipping to control updates
b) Uses value-based learning
c) Runs on multiple GPUs
d) Ignores the policy loss
8. Key Takeaways & Summary
✅ PPO is a policy-based RL algorithm that improves training stability.
✅ It clips policy updates to avoid large, unstable changes.
✅ PPO is widely used in gaming, robotics, trading, and automation.
✅ It balances exploration and exploitation better than older methods.
✅ Implementing PPO is easy with Stable-Baselines3 and OpenAI Gym.
Next Blog- Deep Reinforcement Learning (A3C)






.jpg)














.jpg)


.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)







































