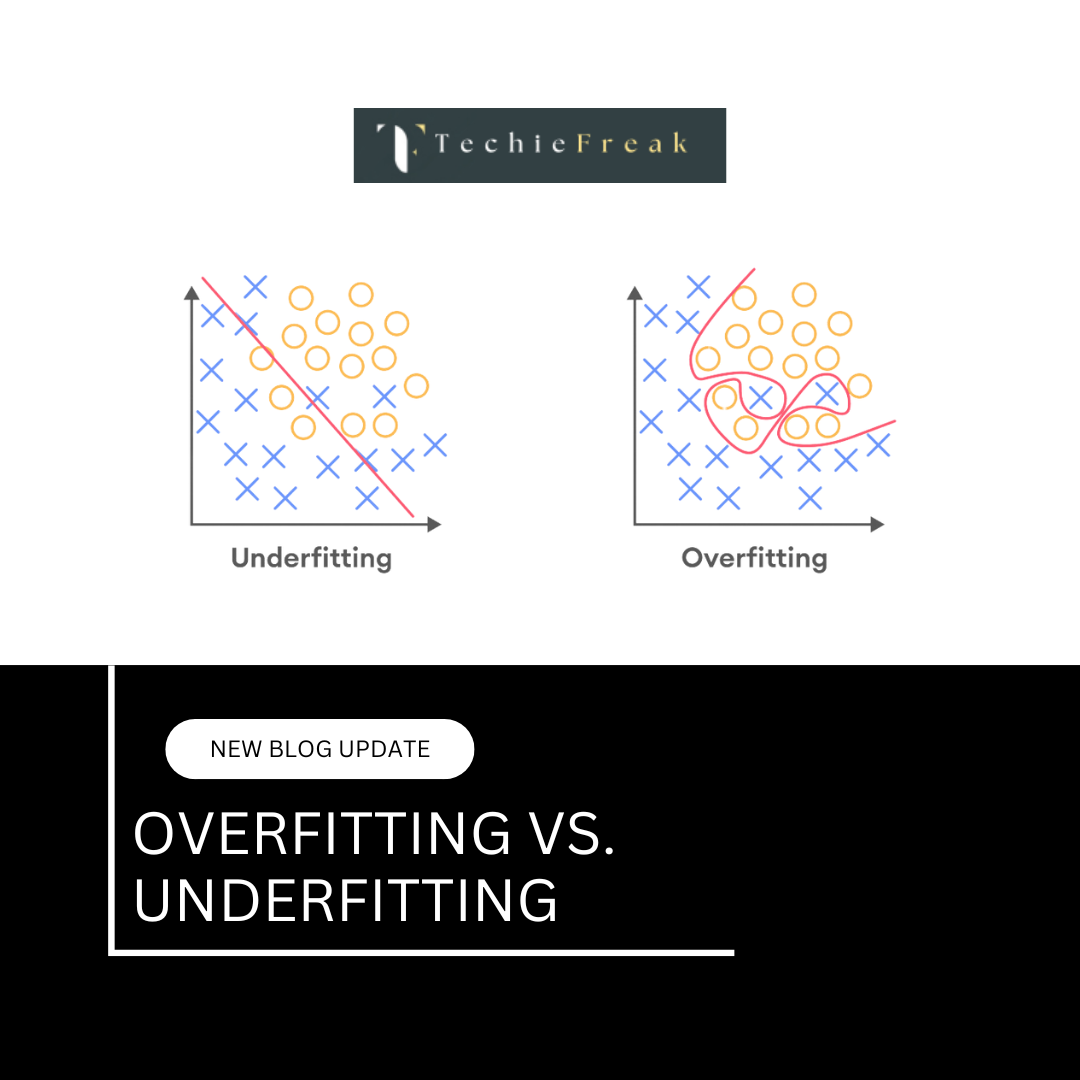
Overfitting vs. Underfitting:
Machine learning models aim to learn patterns from data and generalize well to unseen examples. However, striking the right balance between learning too much (overfitting) and too little (underfitting) is crucial for building effective models. In this guide, we will explore overfitting and underfitting, their impact on model performance, and techniques to detect and mitigate them.
What is Overfitting?
Overfitting occurs when a machine learning model learns the training data too well, capturing noise and random fluctuations rather than general patterns. This results in excellent performance on training data but poor generalization to new data.
Causes of Overfitting
- Excessively complex models: Too many parameters can cause a model to memorize the training data.
- Insufficient training data: The model may learn specific details rather than general patterns.
- Too many features: Irrelevant or redundant features increase the likelihood of memorization.
- Noisy data: Outliers and errors in training data can mislead the model.
How to Detect Overfitting?
- Training accuracy is much higher than test accuracy
- High variance: Small changes in input data drastically alter predictions
- Poor performance on new or unseen data
- High complexity models fitting all data points, including noise
What is Underfitting?
Underfitting happens when a model is too simple to capture the underlying patterns in the data. This results in poor performance on both training and test datasets.
Causes of Underfitting
- Overly simplistic models: Too few parameters to capture the data's complexity.
- Insufficient training time: The model hasn’t learned enough patterns.
- Excessive regularization: Constraints on the model limit its learning capacity.
- Poor feature selection: Not enough relevant features are provided for training.
How to Detect Underfitting?
- Low accuracy on both training and test data
- High bias: Model assumptions are too restrictive
- Fails to capture trends and patterns in the data
- Large errors across all predictions
Techniques to Detect and Mitigate Overfitting
Overfitting happens when a machine learning model learns patterns that are too specific to the training data, including noise and random fluctuations. This reduces its ability to generalize to unseen data. The following techniques help detect and reduce overfitting:
1. Regularization
Regularization adds penalties to the model's complexity, preventing it from memorizing noise and ensuring it generalizes better.
- L1 Regularization (Lasso Regression):
- It adds an absolute value penalty (|W|) to the model’s loss function.
- This results in some feature weights being shrunk to zero, effectively selecting only the most important features and removing redundant ones.
- Use case: Feature selection in high-dimensional datasets.
- L2 Regularization (Ridge Regression):
- It adds a squared penalty (W²) to prevent excessively large weight values.
- This helps reduce model complexity without eliminating features entirely.
- Use case: Helps when all features contribute to the prediction but need controlled influence.
- Dropout (for Neural Networks):
- Dropout randomly disables a fraction of neurons during training, forcing the network to learn multiple independent patterns rather than relying on specific neurons.
- Use case: Deep learning models to prevent over-reliance on particular nodes.
2. Pruning (for Decision Trees and Random Forests)
Pruning reduces the size of decision trees by cutting unnecessary branches, ensuring that the tree does not become too complex.
- Types of Pruning:
- Pre-pruning: Stops tree growth early by setting a maximum depth or requiring a minimum number of samples in a leaf node.
- Post-pruning: Trains the full tree and then removes branches that do not improve accuracy on validation data.
- Why it works:
- Prevents the model from fitting to noise in the training data.
- Reduces variance and improves generalization.
3. Cross-Validation
Cross-validation is a technique to assess a model's performance by dividing the dataset into multiple subsets and training/testing on different splits.
- K-Fold Cross-Validation:
- The data is split into K parts (e.g., K=5), and the model is trained on K-1 parts while testing on the remaining part. This process repeats K times.
- Helps get a more reliable estimate of model performance.
- Stratified K-Fold Cross-Validation:
- Ensures that each fold maintains the same proportion of different classes as the original dataset (important for imbalanced datasets).
- Why it works:
- Reduces dependence on a single train-test split.
- Helps detect overfitting by checking if validation accuracy drops significantly compared to training accuracy.
4. Data Augmentation
Data augmentation artificially expands the training dataset by making minor modifications to existing samples, helping the model learn more general patterns.
- For Image Data:
- Rotation, Cropping, Flipping, Adjusting Brightness, Adding Noise
- Prevents the model from memorizing specific image patterns.
- For Text Data:
- Synonym Replacement, Paraphrasing, Back Translation (translating to another language and back)
- Helps ensure that the model generalizes better to different writing styles.
- Why it works:
- Increases the diversity of the training dataset.
- Makes the model robust to variations and reduces overfitting.
5. Feature Selection and Dimensionality Reduction
Too many features can lead to overfitting, as the model may pick up noise instead of meaningful patterns. Reducing the number of features can simplify the model and improve generalization.
- Principal Component Analysis (PCA):
- Reduces the dataset’s dimensionality while preserving important information.
- Converts features into a smaller set of uncorrelated principal components.
- Recursive Feature Elimination (RFE):
- Recursive Feature Elimination (RFE) is a feature selection technique used in machine learning to identify and retain the most important features while removing irrelevant or less significant ones. It works by iteratively training the model and eliminating the weakest features until the optimal set is found.
- Iteratively removes the least important features based on model performance.
- Helps keep only the most significant features.
- Why it works:
- Eliminates redundant or irrelevant features that contribute to overfitting.
- Improves training efficiency and prevents the model from memorizing unnecessary details.
Techniques to Address Underfitting
Underfitting occurs when a machine learning model is too simple to capture the underlying patterns in the data. It results in high bias and poor performance on both training and test data. The following techniques help to address underfitting:
1. Increase Model Complexity
A model that is too simple may fail to capture the complexities in the data. Increasing its complexity allows it to learn more patterns.
How to Increase Complexity:
- Switch to a more complex model:
- Example: Moving from Linear Regression → Polynomial Regression to capture nonlinear relationships.
- Example: Using a deeper neural network instead of a shallow one.
- Increase the number of features:
- Adding relevant features can improve model performance.
Example in Python:
from sklearn.preprocessing import PolynomialFeatures
from sklearn.linear_model import LinearRegression
from sklearn.pipeline import make_pipeline
# Increase complexity by using polynomial regression
poly_model = make_pipeline(PolynomialFeatures(degree=3), LinearRegression())
Why it works?
- A more complex model can capture intricate relationships that a simple model might miss.
2. Train for a Longer Duration
Some models, especially deep learning models, may not reach optimal performance if training is stopped too early.
How to Train Longer:
- Increase the number of epochs in deep learning models.
- Use early stopping carefully to prevent premature termination.
Example in Neural Networks:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
model = Sequential([
Dense(64, activation='relu', input_shape=(10,)),
Dense(32, activation='relu'),
Dense(1)
])
# Train for a longer duration
model.compile(optimizer='adam', loss='mse')
model.fit(X_train, y_train, epochs=100) # Increase epochs
Why it works?
- Training longer allows the model to learn more complex representations.
3. Reduce Regularization
Regularization prevents overfitting, but too much of it can cause underfitting by limiting the model’s ability to learn.
How to Reduce Regularization:
- Decrease the L1 (Lasso) and L2 (Ridge) penalties in models.
- Reduce dropout rate in neural networks.
Example of Reducing Regularization (Ridge Regression):
from sklearn.linear_model import Ridge
# Reduce regularization strength (alpha)
ridge = Ridge(alpha=0.1) # Lower value means less regularization
ridge.fit(X_train, y_train)
Why it works?
- Less regularization allows the model to learn more details from data.
4. Feature Engineering
Feature engineering involves creating new, more informative features to help the model learn better.
Ways to Engineer Features:
- Polynomial Features: Create interaction terms.
- Feature Scaling: Normalize or standardize data.
- Extract Information: Example: Extracting year, month, and day from a date column.
Example of Feature Engineering:
# Creating new feature (interaction between two variables)
df['new_feature'] = df['feature1'] * df['feature2']
Why it works?
- Better features make it easier for the model to understand patterns.
5. Increase Training Data
More data helps improve model accuracy by providing a better representation of real-world variations.
How to Increase Training Data:
- Collect more real-world data.
- Use Data Augmentation:
- Image data: Rotate, flip, crop images.
- Text data: Paraphrasing, synonym replacement.
Example of Data Augmentation in Images (TensorFlow/Keras):
from tensorflow.keras.preprocessing.image import ImageDataGenerator
datagen = ImageDataGenerator(rotation_range=30, width_shift_range=0.2, height_shift_range=0.2, horizontal_flip=True)
datagen.fit(X_train) # Apply augmentations
Why it works?
- More data provides better generalization and reduces bias.
Finding the Right Model Complexity
Balancing model complexity is key to avoiding both overfitting and underfitting:
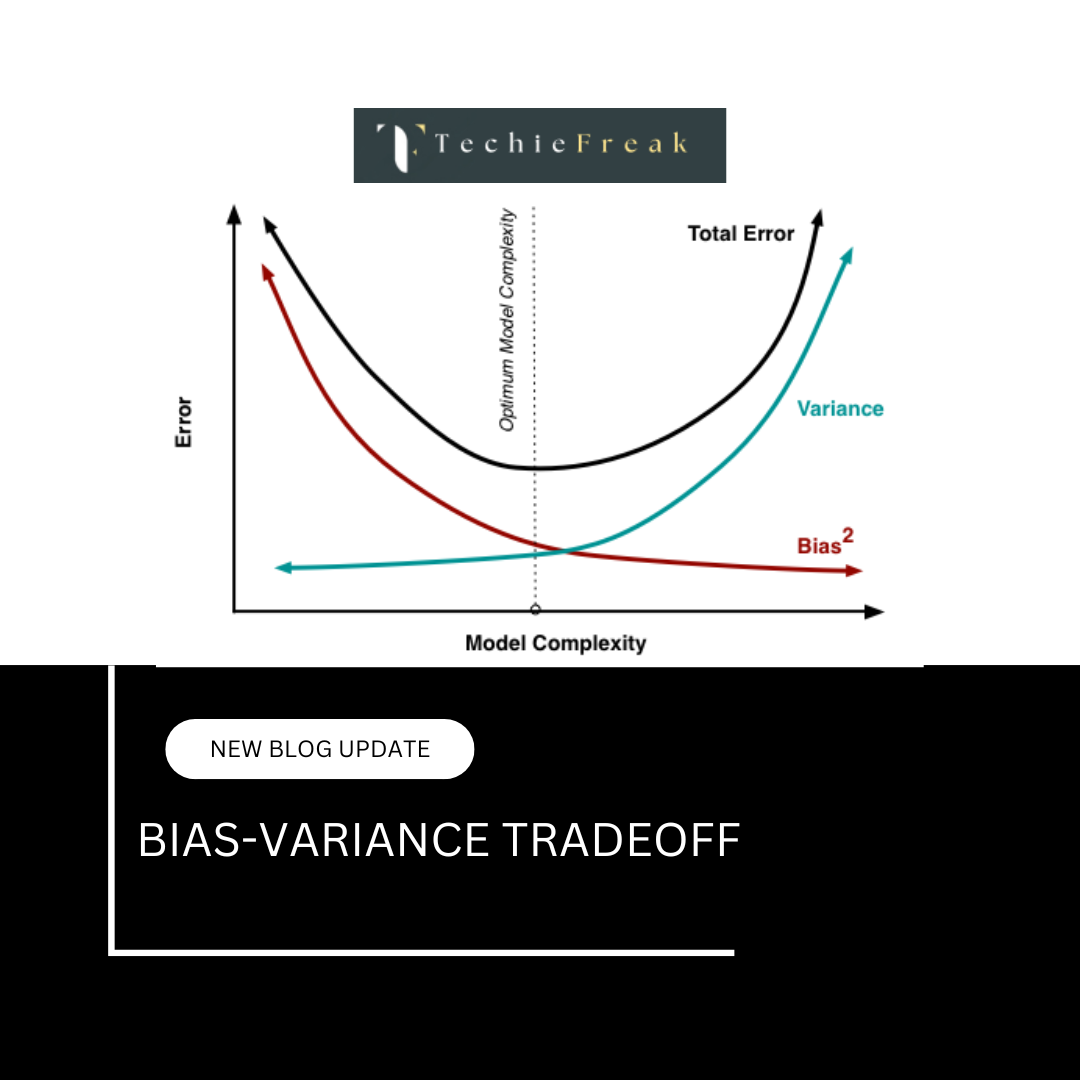
- Bias-Variance Tradeoff: A tradeoff between model simplicity (bias) and complexity (variance) must be achieved.
- Use Learning Curves: Plotting training vs. validation error over epochs can indicate if the model is overfitting or underfitting.
- Tune Hyperparameters: Adjusting model parameters using Grid Search or Random Search can help optimize performance.
Key Takeaways
Overfitting vs. Underfitting: Overfitting happens when a model learns too much from training data, capturing noise rather than patterns. Underfitting occurs when a model is too simple to learn patterns effectively.
Techniques to Detect and Mitigate Overfitting:
- Regularization (L1/L2, Dropout) controls model complexity.
- Pruning reduces unnecessary complexity in decision trees.
- Cross-validation helps assess generalization.
- Data Augmentation increases data diversity.
- Feature Selection & Dimensionality Reduction eliminate redundant features.
Techniques to Address Underfitting:
- Increase Model Complexity (e.g., Polynomial Regression, deeper neural networks).
- Train for a Longer Duration to allow the model to learn better.
- Reduce Regularization to give the model more flexibility.
- Feature Engineering helps create more informative inputs.
- Increase Training Data to enhance model learning and generalization.
Recursive Feature Elimination (RFE): A powerful technique to remove less important features iteratively and improve model performance.
By balancing model complexity, proper training duration, and feature selection, you can build machine-learning models that generalize well and perform optimally!
Next Blog- Bias-Variance Tradeoff




.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)