
Splitting Data into Training and Testing Sets in Machine Learning
In the world of machine learning (ML), one of the most crucial steps is the division of your dataset into training and testing sets. This division is key to building a model that not only performs well on the data it has seen but also generalizes to new, unseen data. In this detailed blog, we will explore why this step is important, how it is done, and best practices for splitting your dataset effectively.
1. Why is Splitting Data into Training and Testing Sets Important?
In machine learning, the ability of a model to perform accurately on unseen data is a key metric for its success. The concept of splitting data into training and testing sets is foundational for ensuring that the machine learning model can generalize well beyond the data it was trained on. This practice prevents models from becoming too specific to the data they have already seen and promotes the development of models that perform effectively on new, real-world data.
Understanding the Need for Splitting Data:
Machine learning models learn by identifying patterns, correlations, and relationships in data. During training, the model uses the features (inputs) and the corresponding target values (outputs) to adjust its internal parameters. The ultimate goal of a machine learning model is not only to perform well on the data it has seen but also to generalize to new, unseen data in a way that accurately predicts the outcome.
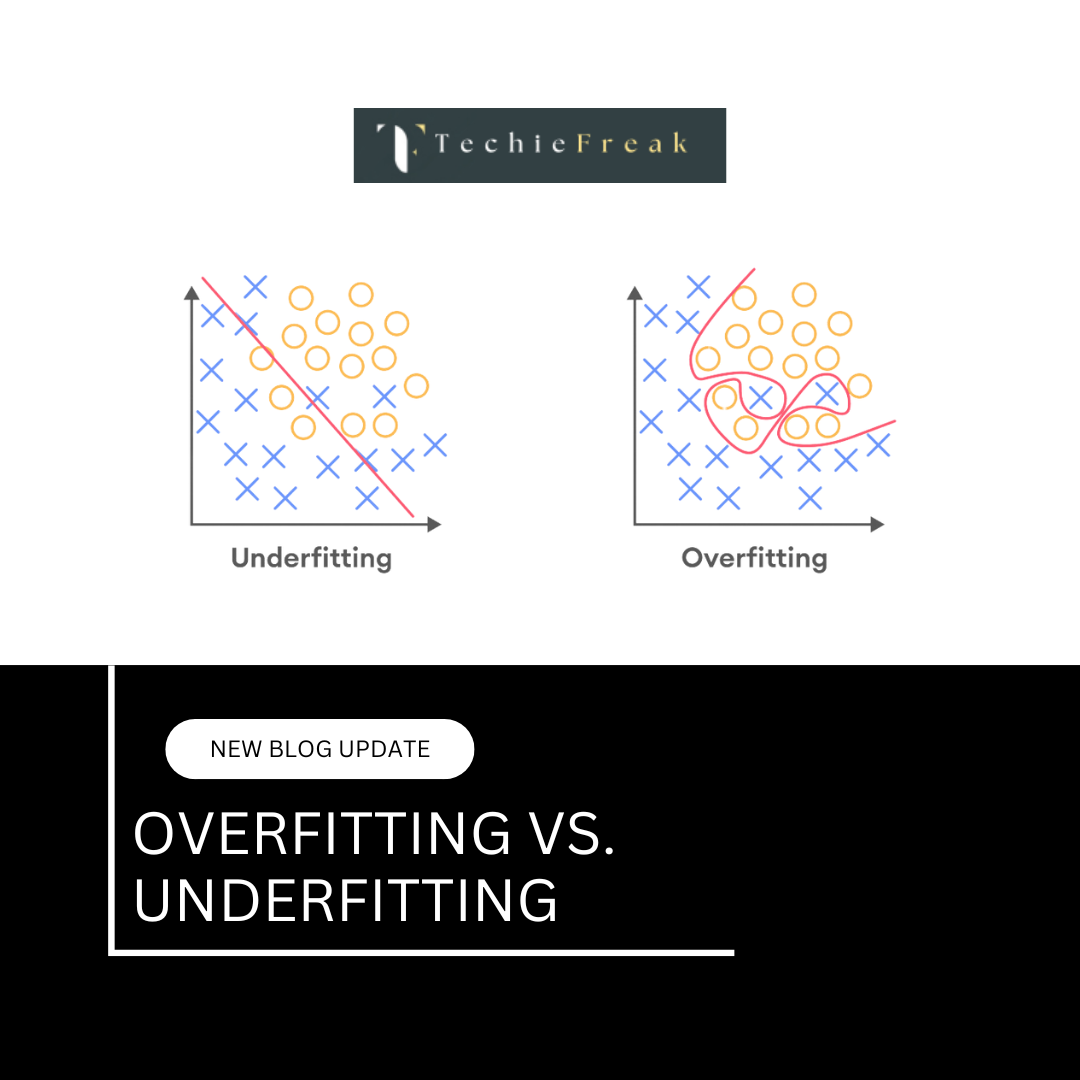
If the model is tested on the same dataset it was trained on, it may achieve perfect accuracy, but this does not guarantee its performance on new data. This scenario can lead to what is known as overfitting — a situation where the model memorizes the training data rather than learning to generalize from it. Overfitting is a common pitfall in machine learning, which is why splitting data into training and testing sets is a critical step to avoid it.
A. Prevents Overfitting:
One of the most significant problems in machine learning is overfitting, which happens when a model is too complex and tries to learn the noise or random fluctuations in the training data, rather than the underlying trend. The result? The model performs well on the training set but struggles to make accurate predictions on new, unseen data.
How Splitting the Data Helps Prevent Overfitting:
- Training Data: During training, the model adjusts its weights and parameters based on the training data. This data should be representative of the kind of data the model will encounter in real-world applications. However, if the model is evaluated on this same data, it may give the illusion of high performance, even if it hasn't truly learned the general trends.
- Testing Data: By testing the model on a separate set of data that it has never seen before, we get a more accurate measure of how well the model is likely to perform on new, unseen examples. This helps to identify whether the model is overfitting (i.e., performing well on training data but poorly on testing data).
The key takeaway: Splitting data ensures the model is not memorizing specific data points but learning generalizable patterns that work on new data.
B. Ensures Model Evaluation:
A model’s true value lies not in its ability to memorize the training data, but in its capacity to generalize—to make predictions on new data that it has not seen during training. Splitting the dataset into training and testing sets allows us to evaluate the model’s real-world performance, helping us gauge its accuracy, precision, recall, and other relevant metrics.
Why Testing on Unseen Data is Vital:
- Model’s True Performance: If you only test your model on the training set, it is difficult to know if it is truly learning meaningful patterns or just memorizing the data. Testing on a separate set provides an unbiased assessment of its accuracy and effectiveness on data it hasn’t encountered before.
- Evaluation Metrics: Performance metrics like accuracy, F1 score, mean squared error (MSE), or area under the curve (AUC) are calculated based on the testing set. This gives us a realistic picture of the model’s ability to make predictions in practical scenarios.
Testing on a separate dataset simulates real-world scenarios where models will face new data daily, making it the most accurate way to assess their true utility.
C. Real-World Simulation:
In real-world applications, machine learning models don’t just operate on data they have already seen—they must work with unseen data in dynamic and evolving environments. Whether you are building a spam filter, a recommendation system, or an image recognition model, the ability of the model to handle data outside the training set is crucial for its success.
How Data Splitting Mimics Real-World Conditions:
- Deployment and Generalization: Once a machine learning model is deployed in the real world, it will face incoming data that is outside of the historical data it was trained on. Splitting the dataset allows us to simulate this real-world challenge of working with unseen data. This process encourages the model to develop generalized patterns rather than memorizing specific details from the training data.
- Performance Prediction: By splitting the data, we can evaluate how the model will behave in real-world situations, which may involve noisy, incomplete, or even adversarial data. This helps to tune the model to perform better under these conditions.
Splitting data reflects the real-world application of the model, where it needs to deal with new inputs consistently and accurately.
D. Helps with Hyperparameter Tuning:
Another important aspect of machine learning is hyperparameter tuning—the process of finding the optimal settings for a model. These parameters, like the learning rate, the number of hidden layers in a neural network, or the regularization strength, can significantly affect model performance.
How Data Splitting Assists in Hyperparameter Tuning:
- Without a separate testing set, there is no clear way to validate whether the hyperparameter choices are beneficial. By splitting the data into training and testing sets, you can experiment with different configurations and evaluate their effectiveness on the testing set before finalizing the model.
- Cross-validation techniques (like k-fold cross-validation) allow you to further refine the model's hyperparameters by evaluating the model on multiple test splits, providing more reliable results.
E. Improves Model Selection:
In machine learning, there are often multiple potential models to choose from. For instance, you might need to decide between logistic regression, decision trees, or neural networks. Data splitting allows you to evaluate how well each model performs on the testing set, helping you choose the best one for your task.
How Splitting Data Supports Model Selection:
- Fair Comparison: With training and testing sets, you can compare models based on their performance on unseen data. This helps to make an informed decision about which model will work best for your problem.
- Avoids Bias: If you were to test multiple models on the same training data, you risk inflating the performance metric because the models may have learned similar patterns from the same dataset. Using a testing set ensures the comparison is fair and unbiased.
F. Helps Manage Data Imbalance:
In real-world datasets, there is often an issue of class imbalance, where one class significantly outnumbers the other (e.g., in fraud detection or disease prediction). If the training set contains too few examples of the minority class, the model may develop a bias toward the majority class.
How Splitting Data Mitigates Data Imbalance:
- Stratified Splitting: By using stratified sampling, you can ensure that both the training and testing sets have a balanced distribution of classes, which improves the model’s ability to learn from minority classes and evaluate its performance accurately.
2. Types of Data Splits in Machine Learning
In machine learning, the way you split your dataset into training and testing sets has a significant impact on the model's performance and evaluation. Depending on the problem you're solving, the size of your dataset, and the characteristics of the data, there are several common data-splitting strategies. These strategies help in ensuring that the model is trained on a representative portion of the data while being tested on unseen data for reliable performance evaluation.
Let’s explore in detail the various types of data splits commonly used in machine learning.
2.1 Simple Train-Test Split
The train-test split is the most basic and widely used technique for splitting data in machine learning. It involves dividing the dataset into two parts: one for training the model and the other for testing the model’s performance.
Key Features of Train-Test Split:
- Training Set: This subset is used to train the machine learning model. The model learns the patterns and relationships in the data based on the features provided.
- Testing Set: This subset is used to evaluate the model’s performance. It helps check how well the model generalizes to new, unseen data.
A typical ratio for splitting data is 80/20 or 70/30, meaning 80% (or 70%) of the data is used for training, and the remaining 20% (or 30%) is used for testing.
Example Scenario:
Let’s assume you have 1,000 data points:
- Training Set: 800 data points (80%).
- Testing Set: 200 data points (20%).
The main advantage of this approach is its simplicity and speed, but a key drawback is that the performance of the model can vary depending on how the data is split. This can be especially problematic with smaller datasets, where a random split might lead to a non-representative training or testing set.
Python Implementation Example:
from sklearn.model_selection import train_test_split
import pandas as pd
# Sample dataset
data = {'Feature1': [1, 2, 3, 4, 5], 'Feature2': [5, 4, 3, 2, 1], 'Target': [0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
# Features and target variable
X = df[['Feature1', 'Feature2']]
y = df['Target']
# Split the dataset into training (80%) and testing (20%) sets
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
# Display the training and testing sets
print("Training Set Features:\n", X_train)
print("Testing Set Features:\n", X_test)
In this example, we use the train_test_split() function from scikit-learn to divide the dataset into training and testing sets. The random_state parameter ensures that the split is reproducible.
2.2 Stratified Train-Test Split
When working with classification problems, especially those involving imbalanced datasets, a simple random split can lead to issues. For instance, in a fraud detection problem, fraudulent transactions may constitute only a small percentage of the total dataset. Randomly splitting the data might result in a training set with very few instances of fraud, making it difficult for the model to learn the important characteristics of fraudulent transactions.
What is Stratified Splitting?
Stratified splitting addresses this issue by ensuring that the distribution of the target variable (i.e., the classes) is preserved in both the training and testing sets. This way, if your dataset has 10% fraud and 90% non-fraud, both the training and testing sets will maintain this 10/90 ratio.
Stratified splitting ensures that the model has enough instances of each class to learn from and evaluates it on a balanced distribution of the classes.
Python Implementation Example:
from sklearn.model_selection import train_test_split
import pandas as pd
# Imbalanced dataset example
data = {'Feature1': [1, 2, 3, 4, 5], 'Target': [0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
# Features and target variable
X = df[['Feature1']]
y = df['Target']
# Perform a stratified split
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, stratify=y, random_state=42)
# Display the training and testing sets
print("Training Set Features:\n", X_train)
print("Testing Set Features:\n", X_test)
In this example, we use the stratify=y parameter to ensure that the target variable's class distribution is preserved across the train and test splits.
2.3 Cross-Validation
While the train-test split is suitable for many cases, it can lead to high variance in model performance, especially when the dataset is small. The performance estimate might vary depending on how the data is split. Cross-validation is an advanced technique used to address this issue by evaluating the model on multiple splits of the data.
What is Cross-Validation?
Cross-validation involves splitting the data into multiple subsets (or folds) and training the model on different combinations of these subsets. One of the most common techniques is k-fold cross-validation. In k-fold cross-validation:
- The dataset is divided into k subsets (or folds).
- The model is trained on k-1 folds and evaluated on the remaining fold.
- This process is repeated k times, each time using a different fold as the test set.
- The final performance is the average of the scores across all k iterations.
This approach helps mitigate the variance in model performance that can arise from a single train-test split. It is particularly useful when dealing with smaller datasets, where using a single split could result in a model being trained on too little data or tested on too little data.
Example with 5-Fold Cross-Validation:
from sklearn.model_selection import cross_val_score
from sklearn.linear_model import LogisticRegression
import pandas as pd
# Sample data
data = {'Feature1': [1, 2, 3, 4, 5], 'Feature2': [5, 4, 3, 2, 1], 'Target': [0, 1, 0, 1, 0]}
df = pd.DataFrame(data)
# Features and target variable
X = df[['Feature1', 'Feature2']]
y = df['Target']
# Cross-validation with logistic regression model
model = LogisticRegression()
scores = cross_val_score(model, X, y, cv=5)
# Display the cross-validation scores
print("Cross-validation scores:", scores)
In this example, we use 5-fold cross-validation (cv=5) to evaluate the model. The cross_val_score function will perform cross-validation by splitting the data into 5 folds, training the model on 4 folds, and testing it on the remaining fold. The final performance is the average of the 5 iterations.
Benefits of Cross-Validation:
- Reduces bias in performance estimation by evaluating the model on multiple data splits.
- Provides a more reliable estimate of the model’s generalization ability, especially for small datasets.
- Helps in detecting overfitting or underfitting by testing the model on different data folds.
3. Best Practices for Splitting Data
Splitting your data into training and testing sets is one of the most crucial steps in building a machine learning model. It ensures that the model is trained on a subset of data and then evaluated on a separate subset, offering a more realistic measure of its performance on unseen data. However, the manner in which this data is split can significantly impact the reliability and accuracy of the model’s evaluation.
In this blog, we’ll explore some of the best practices for splitting data to ensure that the model evaluation is reliable and meaningful.
3.1 Use a Random Seed for Reproducibility
One of the most common practices when splitting data is setting a random seed (or random_state in many libraries). A random seed ensures that the data split remains the same each time you run your model. Without a random seed, the split would change with each execution, leading to potentially inconsistent results.
Why is Reproducibility Important?
Reproducibility is essential for debugging and validating your model. By setting the random seed, you ensure that anyone running the code or reproducing your work gets the same split. This consistency allows you to compare results across different runs, models, or configurations with confidence. It also helps other data scientists or team members who need to reproduce your work.
How to Set a Random Seed?
In Python, you can use libraries like scikit-learn to split data and set the random seed using the random_state parameter. Here’s an example using train_test_split from scikit-learn:
from sklearn.model_selection import train_test_split
# Example data X and y
X = ... # Features
y = ... # Target
# Split the data with a fixed random state
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
In the code above, setting random_state=42 ensures that the data is split in the same way each time the code is run, allowing for reproducible results.
3.2 Consider Time Series Data
When working with time-series data, the regular practice of randomly splitting the data into training and testing sets may not be suitable. Time-series data has a temporal component, meaning that the data points are ordered in time. Randomly splitting this data could cause data leakage (discussed later) or result in unrealistic evaluations since future data would be used to predict past data.
Sequential Splitting for Time-Series Data:
For time-series problems, it is important to preserve the chronological order of data. This can be achieved by sequential splitting, where you use the earlier portion of the data for training and the later portion for testing. This way, the model only learns from past data and is evaluated on future data, just like it would be in real-world applications.
Example:
Let’s assume we have time-series data from 2010 to 2020. Instead of randomly splitting the data, we can use the first portion (2010-2018) for training and the latter portion (2019-2020) for testing.
# Example of sequential split for time-series data
train_data = data[data['Year'] < 2019] # Data from 2010 to 2018 for training
test_data = data[data['Year'] >= 2019] # Data from 2019 to 2020 for testing
This approach mimics the real-world scenario of predicting future events based on historical data, ensuring that the evaluation of the model is aligned with the way the model would be used in production.
3.3 Avoid Data Leakage
Data leakage is one of the most common and detrimental problems in machine learning. It occurs when information from outside the training set is used to create the model, causing it to overestimate its performance. This often happens during feature engineering, where data from the test set inadvertently influences the training process, or when the split between training and testing data is improperly handled.
What is Data Leakage?
Data leakage can happen in a variety of ways:
- Features derived from future information: In time-series forecasting, using future data points or variables that would not be available at the time of prediction can lead to data leakage.
- Feature engineering errors: Sometimes, when creating new features from the entire dataset (including test data), you might accidentally include information from the test set, which leads to an unfair advantage during training.
- Target leakage: If features used for training are directly related to the target variable, it could lead to a model that learns the answer too easily, rendering the evaluation unrealistic.
How to Prevent Data Leakage:
- Separate Training and Testing Data from the Start: Ensure that your training and testing datasets are completely separated right from the data preprocessing stage. Perform all transformations, such as normalization, feature selection, or feature engineering, only on the training data and then apply them to the testing data. This avoids using information from the test set in the training process.
- Feature Engineering with Caution: Be careful when creating new features. If your features involve temporal information, ensure that they do not reference future data that would not be available at the time of prediction. Also, ensure that you don’t leak data from the test set into your feature generation process.
- Cross-Validation: When performing k-fold cross-validation, it’s crucial that the data split ensures that data leakage does not occur. For instance, ensure that each fold of the cross-validation process uses distinct training and testing sets.
- Be Mindful of Data Scaling: For some models, scaling or normalizing features is essential. When applying scaling or transformations, ensure that the scaling parameters (e.g., mean and standard deviation for normalization) are computed only from the training data and then applied to the test data.
Example: Avoiding Data Leakage in Feature Engineering
Suppose you are building a predictive model to estimate customer churn. If you use the target variable (churn) itself to create features, such as "churn in the past 30 days," you would have target leakage. This information is directly related to the target variable and will unfairly influence the model.
# Incorrect example (target leakage)
data['previous_churn'] = data['churn'].shift(30) # This will use future churn data
To avoid this issue, you should engineer features that do not directly use the target variable, ensuring the model learns patterns based on the input features rather than direct leakage from the target.
Key Takeaways
Splitting your dataset into training and testing sets is a crucial step in the machine learning pipeline. It ensures that the model is trained on data it has not seen and is evaluated on new, unseen data. Depending on the problem, different strategies can be used, including a simple train-test split, stratified splits, and cross-validation. By following best practices such as using random seeds, considering data types (e.g., time series), and avoiding data leakage, you can build more reliable and generalizable machine learning models.
Next Topic : Supervised Learning



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)