
Feature Engineering in Machine Learning
Feature Engineering is a crucial step in the machine learning pipeline. It involves transforming raw data into meaningful features that improve the performance of machine learning models. The quality of features plays a significant role in the effectiveness of a model; well-engineered features can make a simple model perform better, while poorly engineered features can lead to subpar results, even with the most complex algorithms.
In this detailed blog, we’ll explore the concept of Feature Engineering, its importance, common techniques, and best practices.
What is Feature Engineering?
Feature engineering is the process of selecting, modifying, or creating new features from raw data that will enhance the performance of machine learning models. It involves transforming existing data into a format that allows the model to learn patterns more effectively.
Feature engineering includes:
- Creating New Features: Combining, transforming, or generating new features from existing ones.
- Selecting Important Features: Identifying and selecting the most important features that significantly impact the target variable.
- Handling Categorical and Numerical Data: Converting raw data into numerical formats or dealing with missing values appropriately.
Why is Feature Engineering Important?
Feature engineering can significantly improve a machine learning model’s accuracy. In many cases, good features can be more important than the choice of algorithm. Here are a few reasons why feature engineering is essential:
- Better Model Performance: Well-designed features can improve model accuracy and help it capture more relevant patterns.
- Model Simplicity: By focusing on relevant features, you can reduce the complexity of the model, making it easier to interpret and faster to train.
- Noise Reduction: Feature engineering helps in filtering out unnecessary features that may introduce noise into the model, allowing it to focus on the most important patterns.
- Handling Data Imbalance: Feature engineering can help address issues like data imbalance by creating features that highlight the patterns in the minority class.
Types of Feature Engineering
Feature engineering is a critical part of the machine learning process. It involves transforming raw data into meaningful features that improve the performance of machine learning models. The effectiveness of a machine learning model depends heavily on the quality of the features used for training. Feature engineering can be broken down into several types based on the nature of the data and the transformations required to make the features suitable for model learning. Let’s take a closer look at these different types of feature engineering.
1. Handling Categorical Data
Categorical features represent discrete values that describe a specific category or group. For instance, data like gender, product type, location, etc., are categorical. Machine learning models typically work with numerical data, so categorical data needs to be transformed into a numerical format. Several methods can be used for this transformation:
1.1 One-Hot Encoding
One-Hot Encoding is a technique used to convert categorical variables into a series of binary (0 or 1) columns, where each column represents one category. For example, if a feature Color contains categories like Red, Blue, and Green, one-hot encoding creates three new columns (Red, Blue, Green), where each category is represented by a binary value of either 0 or 1.
Example:
import pandas as pd
df = pd.DataFrame({'Color': ['Red', 'Blue', 'Green', 'Red']})
df_encoded = pd.get_dummies(df, columns=['Color'])
print(df_encoded)
Output:
Color_Red Color_Blue Color_Green
0 1 0 0
1 0 1 0
2 0 0 1
3 1 0 0
1.2 Label Encoding
Label Encoding assigns a unique integer value to each category in the data. This method is typically used for ordinal categorical variables, where the categories have an inherent order, like low, medium, and high. It converts each category into a distinct integer value.
Example:
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
df['Color_encoded'] = le.fit_transform(df['Color'])
print(df)
Output:
Color Color_encoded
0 Red 2
1 Blue 0
2 Green 1
3 Red 2
1.3 Target Encoding
Target Encoding involves encoding categorical features by calculating the mean of the target variable for each category. This is useful when the number of categories is large and there’s a relationship between the feature and the target.
Example:
import pandas as pd
df = pd.DataFrame({
'Color': ['Red', 'Blue', 'Green', 'Red'],
'Target': [1, 0, 1, 0]
})
target_mean = df.groupby('Color')['Target'].mean()
df['Color_encoded'] = df['Color'].map(target_mean)
print(df)
Output:
Color Target Color_encoded
0 Red 1 0.5
1 Blue 0 0.0
2 Green 1 1.0
3 Red 0 0.5
2. Handling Numerical Data
Numerical features, such as age, income, or height, represent continuous values. These features need to be processed in a way that makes them easier for the machine learning model to interpret. Some common techniques for handling numerical data include:
2.1 Normalization
Normalization is the process of scaling numerical data to a specific range, typically between 0 and 1. This is particularly useful for algorithms like gradient descent, which can perform better when the data has the same scale. For example, if the age and salary features have very different scales, normalization ensures both features contribute equally to the model’s performance.
Example:
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
df[['Age', 'Salary']] = scaler.fit_transform(df[['Age', 'Salary']])
2.2 Standardization
Standardization, also known as Z-score normalization, transforms data to have a mean of 0 and a standard deviation of 1. It’s commonly used when the data follows a Gaussian (normal) distribution, and it's crucial for algorithms like Support Vector Machines (SVM) and k-NN, which are sensitive to the magnitude of data.
Example:
from sklearn.preprocessing import StandardScaler
scaler = StandardScaler()
df[['Age', 'Salary']] = scaler.fit_transform(df[['Age', 'Salary']])
2.3 Binning
Binning is the process of converting numerical data into discrete intervals or bins. For example, the age feature can be converted into age ranges like "<20", "20-30", etc. Binning is useful when the data has a large spread and can be grouped into categories for simplicity.
Example:
df['Age_bins'] = pd.cut(df['Age'], bins=[0, 20, 30, 40, 50], labels=['<20', '20-30', '30-40', '40-50'])
3. Feature Creation
Feature creation is the process of creating new features from existing data to enhance the model’s performance. This involves generating more informative features that better capture the underlying patterns in the data.
3.1 Polynomial Features
Polynomial features involve creating interaction terms by raising features to higher powers or multiplying them together. This method is useful for capturing non-linear relationships between features.
Example:
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
df_poly = poly.fit_transform(df[['Age', 'Salary']])
3.2 Date and Time Features
Many datasets contain date and time information, which can be extracted into useful features. For example, you can extract the day of the week, month, or year from a date column. Other derived features like whether a date is a weekend or a holiday can also provide valuable insights.
Example:
df['Day_of_week'] = df['Date'].dt.dayofweek
df['Is_weekend'] = df['Day_of_week'].isin([5, 6])
3.3 Text Features
Text data can be converted into numerical features using techniques like Bag of Words, TF-IDF (Term Frequency-Inverse Document Frequency), or Word Embeddings. These techniques allow the machine learning model to understand and learn from text-based data.
Example:
from sklearn.feature_extraction.text import TfidfVectorizer
vectorizer = TfidfVectorizer()
X = vectorizer.fit_transform(df['text_column'])
4. Feature Selection
Feature selection is the process of identifying the most relevant features for the model while discarding irrelevant or redundant ones. The goal is to improve model performance and reduce overfitting.
4.1 Correlation Matrix
A correlation matrix can be used to identify highly correlated features. If two features have a very high correlation (above a threshold), one of them can be dropped to reduce redundancy.
Example:
corr = df.corr()
print(corr)
4.2 Recursive Feature Elimination (RFE)
Recursive Feature Elimination (RFE) is a feature selection technique that recursively removes the least important features based on model performance. RFE selects the most important features by evaluating the model’s performance after each feature elimination.
Example:
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
model = LogisticRegression()
rfe = RFE(model, 5)
X_rfe = rfe.fit_transform(df[['Age', 'Salary', 'Gender']], df['Target'])
4.3 L1 Regularization (Lasso)
Lasso regression applies L1 regularization, which penalizes the absolute values of the model’s coefficients. It drives less important feature coefficients towards zero, effectively eliminating them from the model. Lasso is useful for feature selection, especially when there are many features.
Example:
from sklearn.linear_model import Lasso
lasso = Lasso(alpha=0.1)
lasso.fit(df[['Age', 'Salary', 'Gender']], df['Target'])
Best Practices for Feature Engineering
Feature engineering is a critical step in building robust machine learning models. It involves transforming raw data into meaningful features that improve model performance. While feature engineering is often considered an art, applying best practices can significantly enhance the process. Let’s delve into some of the most important practices to keep in mind when performing feature engineering.
1. Understand the Data
Before diving into feature engineering, it’s essential to thoroughly understand the data you’re working with. Domain knowledge plays a crucial role in ensuring the transformation you apply is relevant and meaningful to the target variable. Here are some tips to help you understand your data better:
- Exploratory Data Analysis (EDA): Use techniques such as visualizations, descriptive statistics, and correlation matrices to identify trends, outliers, and relationships between features.
- Feature Relationships: Understand the relationship between features and the target variable. Some features may have strong predictive power, while others might be irrelevant or even harmful.
- Data Types: Recognize the types of features you’re working with—categorical, numerical, text, or time-based. The type of feature will determine the transformation or encoding technique you use.
- Missing Data: Address any missing data issues early. Missing values can often cause models to underperform, so handling them (through imputation, removal, or other methods) is key.
By fully understanding the data, you ensure that the transformations and feature selection steps align with the business problem or research question you are trying to solve.
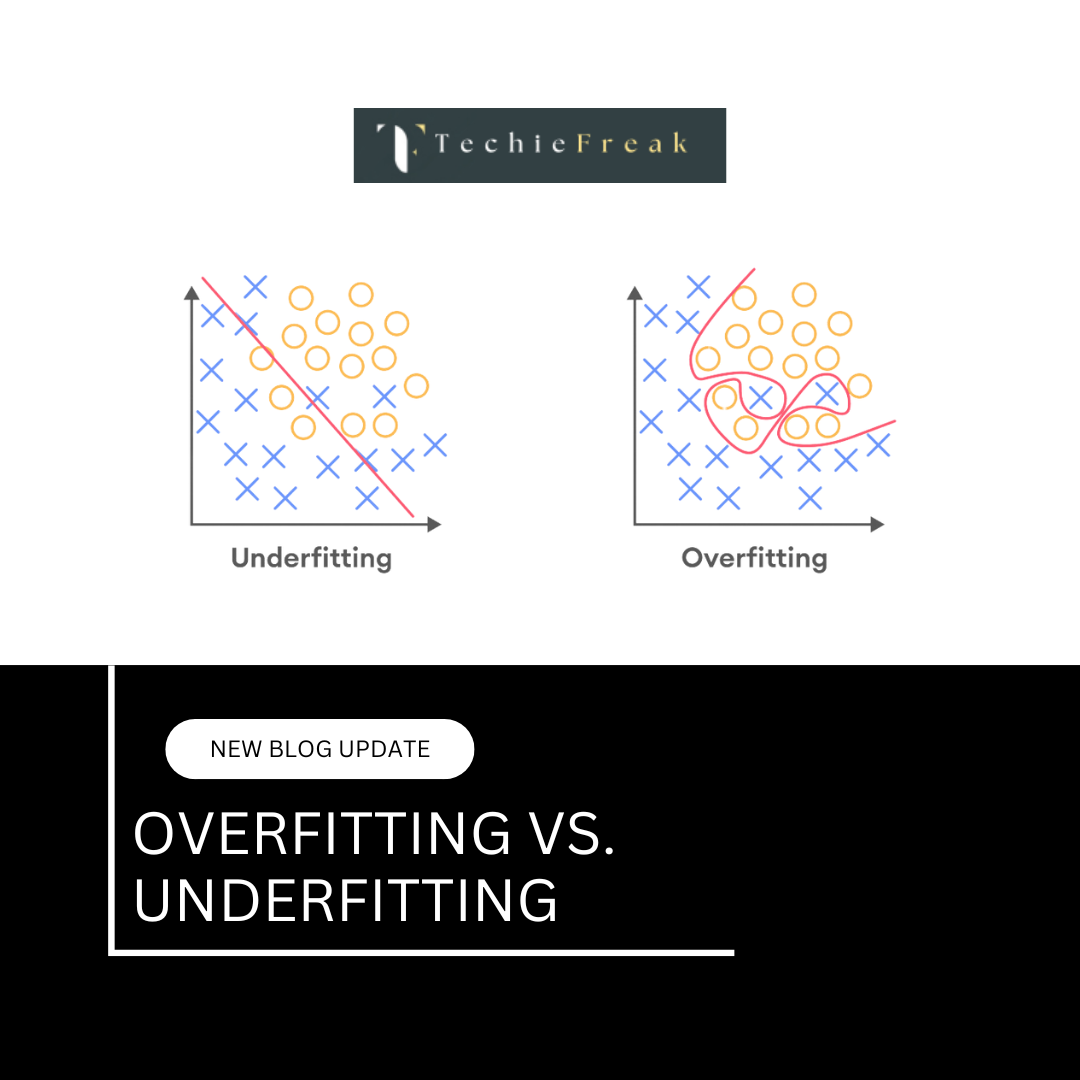
2. Avoid Overfitting
While it’s tempting to create complex features in an effort to capture more detailed patterns in the data, this can lead to overfitting—especially when you have a small dataset. Overfitting occurs when a model learns patterns from the training data that do not generalize well to unseen data.
Best practices to avoid overfitting:
- Feature Complexity: Avoid creating overly complex features, as they might capture noise instead of meaningful patterns. For instance, polynomial features can help in capturing non-linearity but should be used with caution, especially for smaller datasets.
- Model Simplicity: When adding new features, evaluate whether they genuinely contribute to improving model accuracy. Sometimes, simpler models with fewer features work better because they generalize more effectively.
- Regularization: Regularization techniques such as L1 (Lasso) or L2 (Ridge) regularization can help control overfitting. They penalize large coefficients and prevent the model from fitting to noise.
- Cross-Validation: Always validate model performance using techniques like cross-validation (which we’ll discuss below) to ensure that the model’s performance holds up on unseen data.
3. Experiment and Iterate
Feature engineering is not a one-time task; rather, it is an iterative and experimental process. Often, the first set of features you create will not yield the best results. By constantly experimenting with new features and transformations, you can discover improvements and fine-tune your model.
How to effectively experiment:
- Start Simple: Begin with simple transformations and feature creation methods. This gives you a baseline to compare against more complex approaches.
- Test New Ideas: Don’t hesitate to try unconventional features that might not be obvious at first. For example, combining two features into an interaction term or adding domain-specific features that reflect your business understanding.
- Feature Importance: After building models, assess the importance of different features using methods like Random Forests or Gradient Boosting. This will help you see which features contribute most to the model's predictions and which ones can be discarded.
- Use Domain Knowledge: Experiment with features that are informed by the business or domain you’re working in. For instance, in a financial fraud detection problem, the ratio of transactions to account age may be more meaningful than just the raw transaction amount.
- Iterative Process: Feature engineering should not be a one-and-done approach. After each round of model training and testing, revisit your feature set and improve it based on insights gained.
4. Use Cross-Validation
Cross-validation is an essential technique in machine learning that involves splitting your data into multiple folds and evaluating model performance across each fold. This is particularly useful when you want to validate the effectiveness of new features or transformations before deploying them into production.
Key reasons to use cross-validation:
- Evaluate Feature Effectiveness: When experimenting with different feature sets, cross-validation helps ensure that new features improve model performance and generalize well across different subsets of data.
- Hyperparameter Tuning: Cross-validation is also used to tune hyperparameters for algorithms. By evaluating different combinations of features and hyperparameters on multiple data splits, you ensure a well-balanced model that avoids overfitting.
- Generalization Testing: It’s important to test how features perform on data that the model hasn’t seen during training. Cross-validation ensures that your model’s performance isn’t a fluke due to a particular split of the data.
- Comparison of Feature Sets: Cross-validation allows you to compare models with and without specific features or transformations, helping you objectively measure which features add the most value.
5. Consider the Computational Cost
Feature engineering is a resource-intensive task, and with larger datasets or more complex transformations, the computational cost can increase significantly. It's essential to balance the benefits of new features with their impact on training time and model performance.
Best practices to consider:
- Efficiency: Some feature transformations (like polynomial feature creation) may introduce high computational costs without adding significant value. Consider the efficiency of your methods and whether they will scale well.
- Dimensionality Reduction: Techniques such as Principal Component Analysis (PCA) or t-SNE can help reduce the number of features when dealing with high-dimensional data. These methods can simplify the model, reduce training time, and prevent overfitting.
- Feature Selection: After creating a range of features, use feature selection techniques like Recursive Feature Elimination (RFE) or mutual information to identify and keep only the most informative features.
6. Understand the Importance of Timing
For time-series data, the timing of feature engineering becomes especially important. Features created from past time steps may be predictive for future observations, but only if you handle the chronological ordering properly.
- Time-based Features: For example, extracting day of the week, month, or hour from a timestamp could help improve predictive performance in time-series forecasting tasks.
- Lag Features: These are features based on previous time steps (lags) that can help the model identify trends and patterns.
- Rolling Windows: Rolling mean or standard deviation over a window can smooth out time series data and provide more informative features.
Key Takeaways
Feature engineering is a vital step in machine learning, and its quality can make a significant difference in model performance. By applying techniques like encoding categorical data, scaling numerical features, creating new features, and selecting the most important ones, data scientists can build models that learn better and perform more accurately. As part of this process, it's essential to leverage domain knowledge, experiment with different strategies, and avoid common pitfalls like overfitting. By focusing on feature engineering, you can improve the predictive power of your models and ensure they are working with the most relevant and useful data.
Next Topic : Data Normalization and Standardization in ML



.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)