.png)
Hyperparameter Tuning in Machine Learning: Grid Search vs. Random Search
Introduction
Hyperparameter tuning is a crucial step in machine learning that optimizes model performance. Unlike model parameters learned from data (such as weights in linear regression), hyperparameters are predefined settings that must be manually selected to improve a model’s accuracy and efficiency. Two widely used methods for tuning hyperparameters are Grid Search and Random Search. This blog explores their differences, efficiency, and use cases.
What Are Hyperparameters, and Why Do They Matter?
Hyperparameters control how a machine learning algorithm learns from data. Selecting the right hyperparameters can significantly impact model accuracy, generalization, and computational efficiency. Examples include:
- Learning rate in gradient-based algorithms
- Number of hidden layers and neurons in neural networks
- Regularization parameters in regression models
- Maximum depth of decision trees
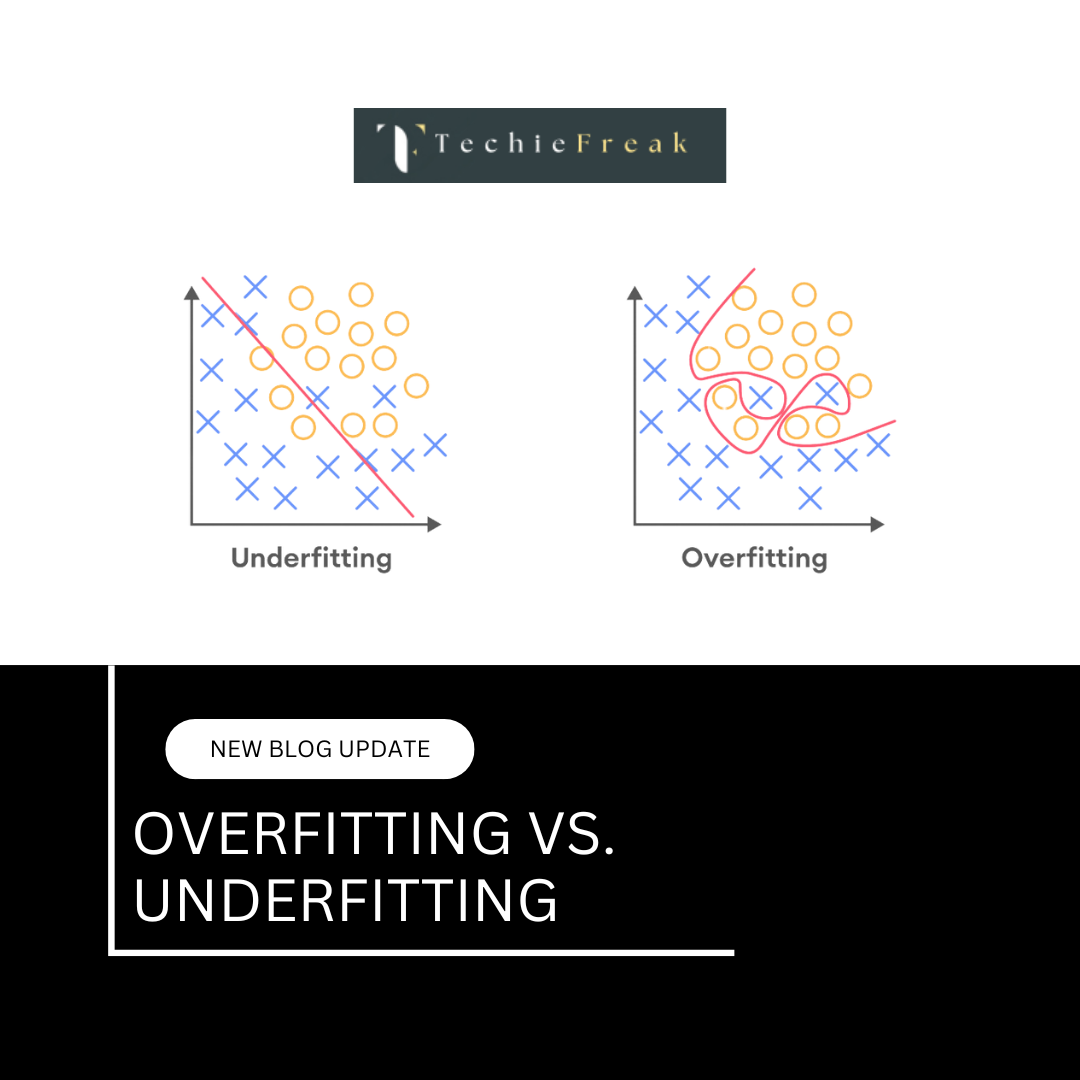
Poorly chosen hyperparameters can lead to underfitting (high bias) or overfitting (high variance), making hyperparameter tuning essential.
Grid Search: How It Works and When to Use It
Grid Search is an exhaustive search technique that evaluates all possible combinations of a set of hyperparameters to find the best-performing configuration.
How Grid Search Works:
- Define a set of hyperparameter values for tuning.
- Train and validate the model on all possible combinations of these values.
- Select the combination that yields the highest performance based on a validation metric (e.g., accuracy, F1-score).
When to Use Grid Search:
- When computational resources are available, as it is computationally expensive.
- When the number of hyperparameters is small.
- When precise tuning of hyperparameters is required.
Pros of Grid Search:
- Finds the optimal hyperparameter combination (within the predefined set).
- Suitable for low-dimensional hyperparameter spaces.
Cons of Grid Search:
- Computationally expensive as it evaluates all possible combinations.
- Inefficient for high-dimensional spaces where many configurations may be unnecessary.
Random Search: How It Differs and When It’s Better
Random Search selects random hyperparameter values within a given range instead of systematically evaluating all possible combinations.
How Random Search Works:
- Define a range of hyperparameter values.
- Randomly sample values within this range.
- Train and validate the model using these random configurations.
- Identify the best-performing hyperparameters.
When to Use Random Search:
- When the hyperparameter space is large and exhaustive search is impractical.
- When computational efficiency is a concern.
- When only a rough tuning of hyperparameters is needed.
Pros of Random Search:
- More efficient than Grid Search for high-dimensional hyperparameter spaces.
- Can find near-optimal solutions with fewer evaluations.
- Works well when only a few hyperparameters significantly affect performance.
Cons of Random Search:
- May miss the absolute best combination since it does not test all possibilities.
- Requires more trials to achieve high precision in low-dimensional problems.
Comparing Grid Search and Random Search: Efficiency, Accuracy, and Performance
| Feature | Grid Search | Random Search |
|---|---|---|
| Efficiency | Slow (tests all) | Faster (tests randomly) |
| Accuracy | Finds best solution | Finds near-optimal solution |
| Computational Cost | High | Lower |
| Best for | Small hyperparameter spaces | Large hyperparameter spaces |
Key Insights:
- Grid Search is best for small, well-defined search spaces where computational resources are available.
- Random Search is more practical for large search spaces and limited computational budgets.
- For deep learning models with extensive hyperparameters, Random Search is often preferred.
Key Takeaways
Hyperparameter tuning is a vital step in building optimized machine learning models. Grid Search is a methodical but computationally expensive approach, while Random Search offers efficiency and flexibility, especially for large search spaces. Choosing between them depends on factors like computational budget, dataset size, and the importance of fine-tuning accuracy.
For real-world applications, Bayesian Optimization and other advanced techniques like Hyperband can further improve hyperparameter tuning efficiency. However, understanding the basics of Grid Search vs. Random Search is a great starting point for optimizing machine learning models effectively.
Next Blog- Cross-Validation Techniques




.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)