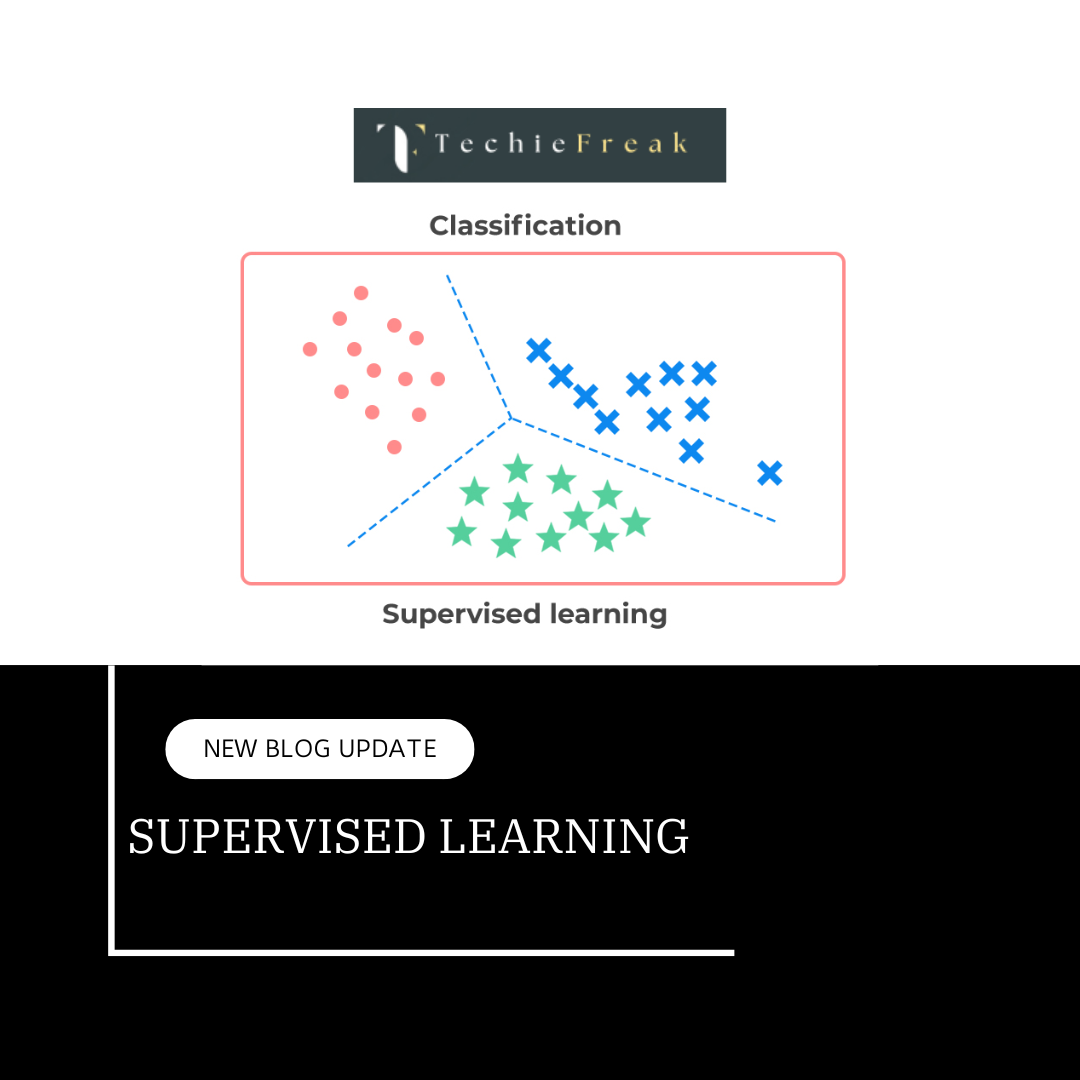
Supervised Learning: An Introduction
Supervised learning is one of the most prominent and widely used types of machine learning algorithms. It refers to a learning method where the model is trained on labeled data, meaning that the input data is paired with the correct output. The primary goal of supervised learning is to learn a mapping function that can predict the output from the input.
What is Supervised Learning?
In supervised learning, the algorithm learns from a dataset that contains both input features and the corresponding output labels. The model uses this data to understand the relationship between the input and output. Once trained, the model can predict the output for new, unseen input data.
The process of supervised learning can be broken down into three key components:
- Training data: This includes labeled data where each input has a corresponding output.
- Model: The machine learning algorithm or system that learns from the data.
- Prediction: After training, the model can make predictions on unseen data.
Types of Supervised Learning
Supervised learning is primarily divided into two categories, depending on the nature of the output variable:
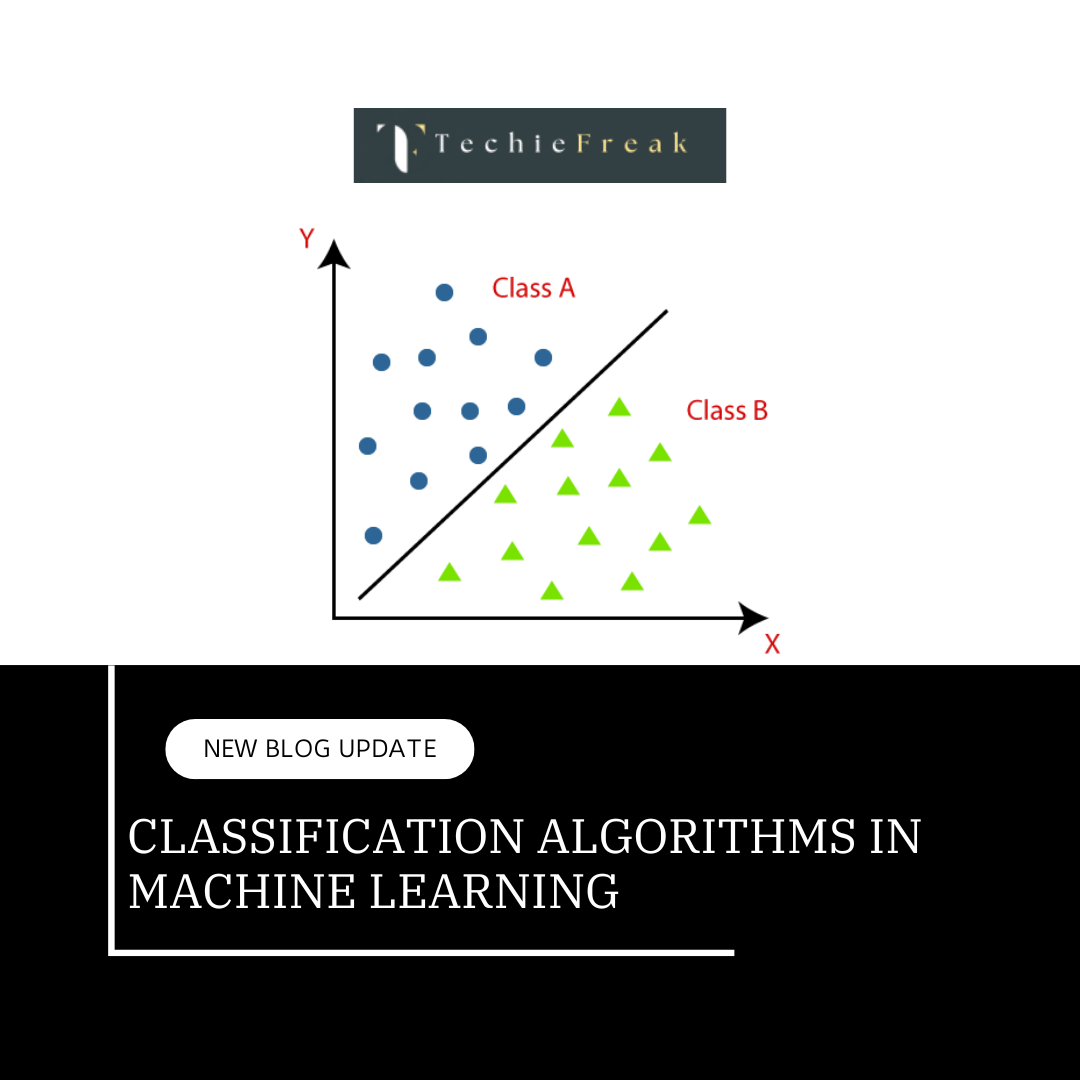
- Classification:
- In classification problems, the output variable is categorical. The goal is to assign input data into predefined categories or classes.
- Examples:
- Email spam detection (spam or not spam).
- Image classification (identifying objects in images such as dogs, cats, etc.).
- Sentiment analysis (positive, negative, or neutral sentiment).
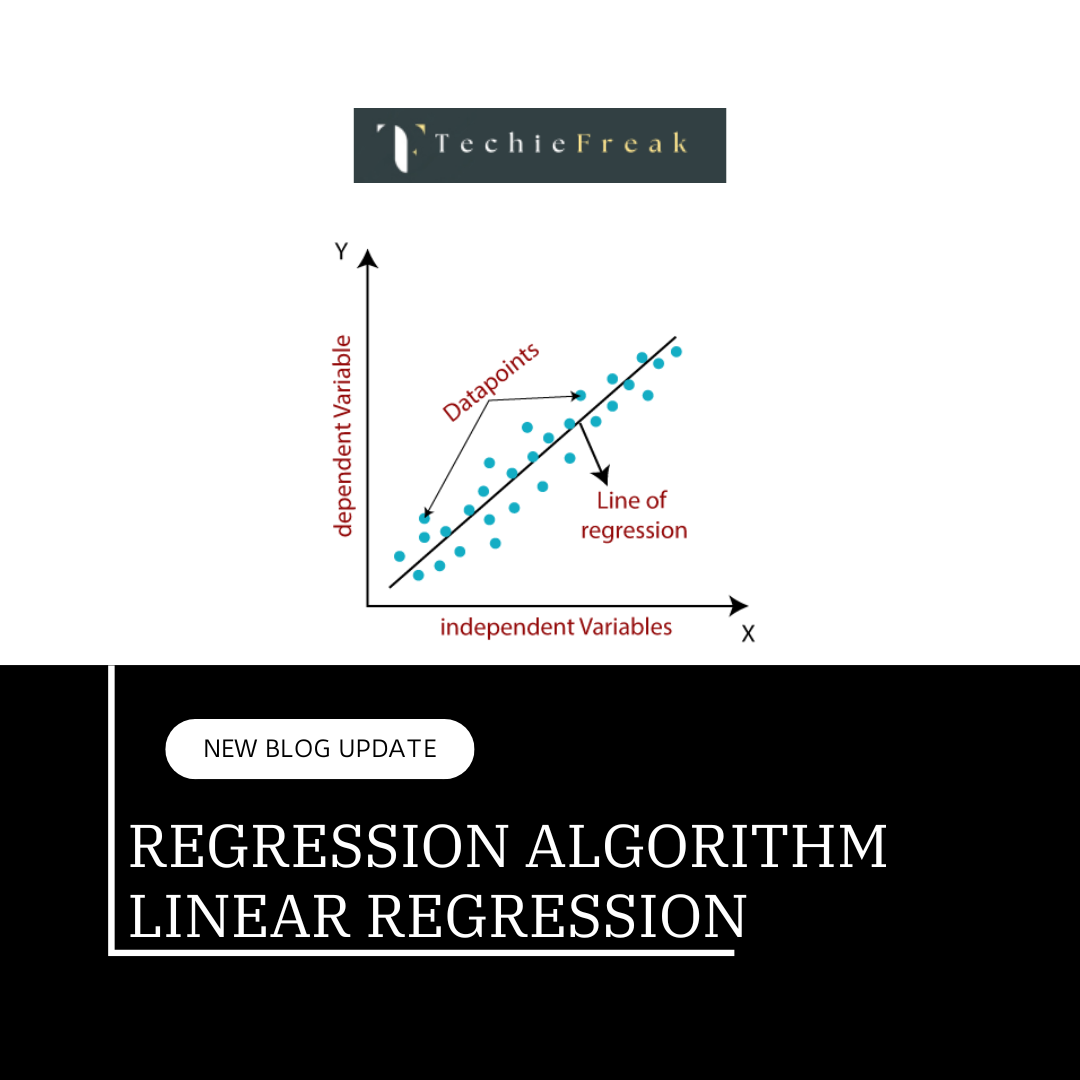
- Regression:
- Regression problems involve continuous output variables. The goal is to predict a continuous value based on the input data.
Examples:
- Predicting house prices based on various factors like area, location, and number of rooms.
- Stock price prediction.
- Forecasting temperature or sales figures.
How Supervised Learning Works
Supervised learning is a type of machine learning where an algorithm learns from labeled data to predict outcomes for new, unseen data. This process involves several steps, each of which is crucial for building an effective machine learning model. Below is a detailed breakdown of how supervised learning works, from data collection to making predictions.
1. Data Collection
The first and most critical step in the supervised learning process is gathering data. For supervised learning, you need labeled data, which means that for each input (feature), there is a corresponding correct output (label). The accuracy and quality of your model depend heavily on the quality of this data.
Data can come from various sources:
- Databases: Structured datasets that can be directly accessed and used for machine learning tasks.
- Sensors: In fields like IoT (Internet of Things) or autonomous vehicles, data might be collected in real-time from various sensors.
- Surveys: Data gathered from questionnaires or forms, often used in healthcare, marketing, and social sciences.
- Web Scraping: For certain applications, data can be collected from websites or other online sources.
For example, in a spam email classification problem, the dataset would consist of labeled examples of emails (input), where each email would be marked as "spam" or "not spam" (output).
2. Data Preprocessing
Once the data is collected, the next step is preprocessing. Raw data typically requires cleaning and transforming before it can be fed into a model. The goal of preprocessing is to convert the data into a suitable format, free of any issues that might hinder the learning process.
Key tasks in data preprocessing include:
- Removing Duplicates: Duplicate records can distort the learning process and reduce the model's ability to generalize. Duplicates are often identified and removed to ensure that each data point is unique.
- Handling Missing Values: Many datasets contain missing or null values. These can be handled in different ways, such as imputing missing values (replacing with the mean, median, or mode) or discarding rows or columns with too many missing values.
- Normalization/Scaling: If the input features have different units or ranges, it's crucial to normalize or scale the data. This ensures that no particular feature dominates due to its larger scale, improving the model's ability to learn. Common methods include:
- Min-Max Scaling: Rescales values to a specific range (usually 0 to 1).
- Standardization: Centers the data around a mean of 0 and scales it to unit variance.
- Encoding Categorical Variables: If the dataset includes categorical data (e.g., color, country, product type), it must be transformed into numerical form using techniques like one-hot encoding or label encoding.
- Splitting the Dataset: It's essential to split the data into two main subsets: the training dataset and the test dataset. The training dataset is used to train the model, while the test dataset is used to evaluate its performance.
3. Model Selection
After preprocessing the data, you need to select an appropriate machine learning algorithm based on the nature of your data and problem. The type of problem you're trying to solve (regression or classification) will determine which algorithm to use.
Here are some commonly used supervised learning algorithms:
- Decision Trees: Decision trees are simple models that split the data into branches based on feature values. They are easy to interpret and can handle both classification and regression tasks.
- Support Vector Machines (SVM): SVM is a powerful algorithm that finds the optimal hyperplane that separates the data into different classes. It works well for both linear and non-linear classification tasks.
- K-Nearest Neighbors (KNN): KNN is a non-parametric algorithm that makes predictions based on the majority class of the k-nearest data points. It is easy to implement but can be computationally expensive for large datasets.
- Linear Regression: Linear regression is used for regression tasks where the goal is to predict a continuous value. It models the relationship between the input variables and the output variable as a linear equation.
- Neural Networks: Neural networks are highly flexible models inspired by the human brain. They are particularly useful for complex tasks like image recognition and natural language processing (NLP). They consist of layers of interconnected nodes (neurons) that process data.
4. Model Training
Once the algorithm is selected, the next step is to train the model. During training, the algorithm learns the relationship between the input features and the output labels. The training process involves feeding the model with the training data and adjusting the model’s parameters to minimize the error between the predicted and actual output.
- For example, in a classification problem, the model might adjust the weights of its parameters to minimize classification errors, such as predicting a "spam" email as "not spam."
- In a regression problem, the algorithm will try to minimize the difference between the predicted continuous value and the actual value using loss functions like Mean Squared Error (MSE).
The model training process often involves using techniques like gradient descent (for adjusting model parameters) or backpropagation (for neural networks).
5. Model Evaluation
After training, the model's performance is evaluated using a separate test dataset that was not part of the training data. This helps determine how well the model generalizes to unseen data. Evaluation is done using specific performance metrics that depend on the task:
- Classification Metrics:
- Accuracy: The percentage of correct predictions out of all predictions.
- Precision: The proportion of positive predictions that are actually correct.
- Recall: The proportion of actual positives that were correctly identified by the model.
- F1 Score: A weighted average of precision and recall, useful for imbalanced classes.
- Regression Metrics:
- Mean Squared Error (MSE): The average of the squared differences between the predicted and actual values.
- R-squared: A measure of how well the model explains the variance in the data.
- Mean Absolute Error (MAE): The average of the absolute differences between the predicted and actual values.
6. Prediction
Once the model has been trained and evaluated, it can be used for predicting outcomes on new, unseen data. This step involves feeding the model with fresh input data, which it uses to generate predictions.
For instance, in a medical diagnosis system, the trained model could predict whether a new patient has a particular disease based on their symptoms and test results. In a recommendation system, it could suggest products based on user preferences.
The accuracy of predictions largely depends on the quality of the training data, the choice of the algorithm, and how well the model was evaluated and optimized.
Use Cases of Supervised Learning
Supervised learning has a broad range of applications in various industries. Some common use cases include:
- Healthcare: Predicting the likelihood of diseases (like cancer detection based on medical images) or identifying potential patients for clinical trials.
- Finance: Fraud detection, credit scoring, and stock market predictions.
- Retail: Customer segmentation, product recommendation systems, and demand forecasting.
- Autonomous Vehicles: Recognizing traffic signs, obstacles, and pedestrian detection.
- Marketing: Customer churn prediction, targeted advertising, and campaign performance analysis.
Challenges in Supervised Learning
While supervised learning is highly effective, it also comes with certain challenges:
- Labeled Data Requirement: The most significant challenge is the need for a large amount of labeled data. Labeling data can be time-consuming and costly, especially for tasks like image recognition or speech processing.
- Overfitting: If a model is too complex, it may fit the training data very well but fail to generalize to new data. Regularization techniques and cross-validation can help mitigate overfitting.
- Bias in Data: If the training data contains bias, the model will likely inherit these biases and make biased predictions. Ensuring data diversity and fairness is crucial.
- Computational Complexity: Some algorithms can be computationally expensive, especially for large datasets. Optimizing algorithms and using efficient hardware can help address this.
Key Takeaways
Supervised learning is a cornerstone of machine learning, enabling machines to learn from labeled data and make predictions or classifications. It has vast applications in fields like healthcare, finance, marketing, and autonomous systems. However, like all machine learning methods, it comes with its own set of challenges that require careful handling of data, model selection, and evaluation.
As the field of machine learning continues to evolve, supervised learning remains a vital tool in the creation of intelligent systems that can analyze data, detect patterns, and make decisions autonomously.

.png)
.png)
.png)

.png)
.png)
.png)
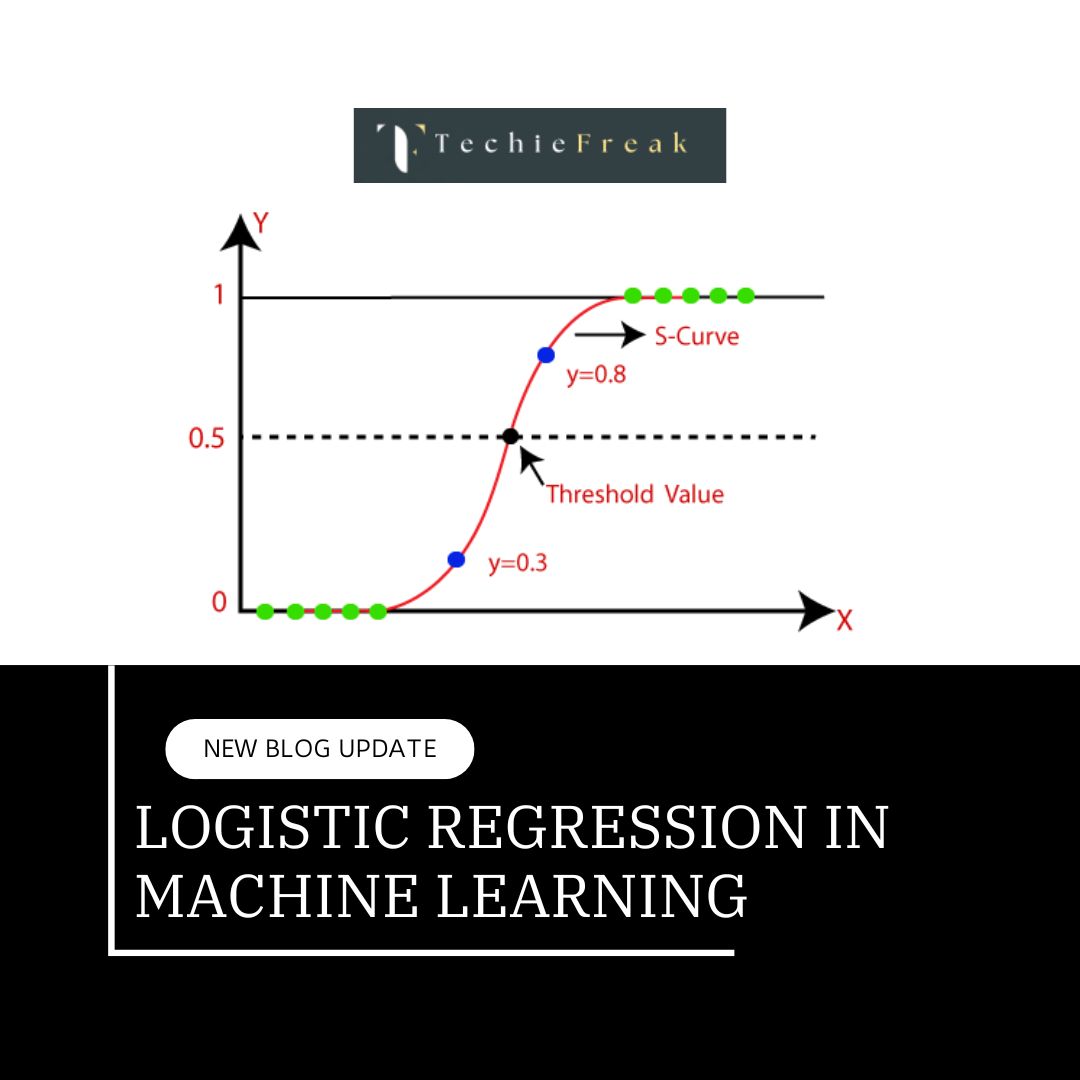
 Algorithm for Machine Learning.jpg)
 Algorithm.jpg)

.png)
.png)
.png)
.png)
.png)
.png)