.png)
Random Forest is a widely used ensemble learning algorithm that enhances the accuracy and stability of machine learning models. It is built upon the concept of Decision Trees and the Bagging (Bootstrap Aggregating) technique to improve predictive performance and minimize overfitting. In this detailed blog, we will delve deep into the workings of Random Forest, its advantages and disadvantages, hyperparameter tuning, and real-world applications.
What is Random Forest?
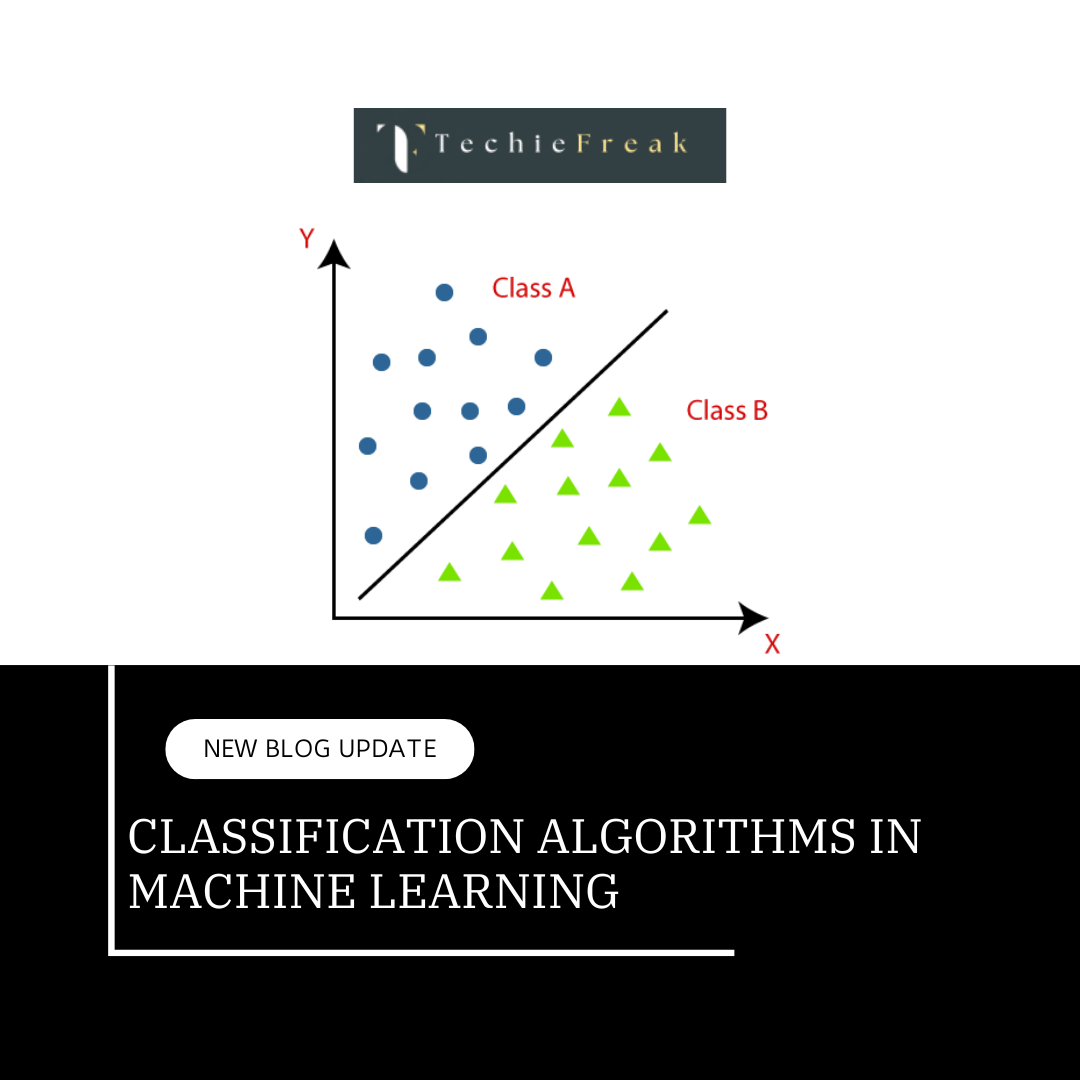
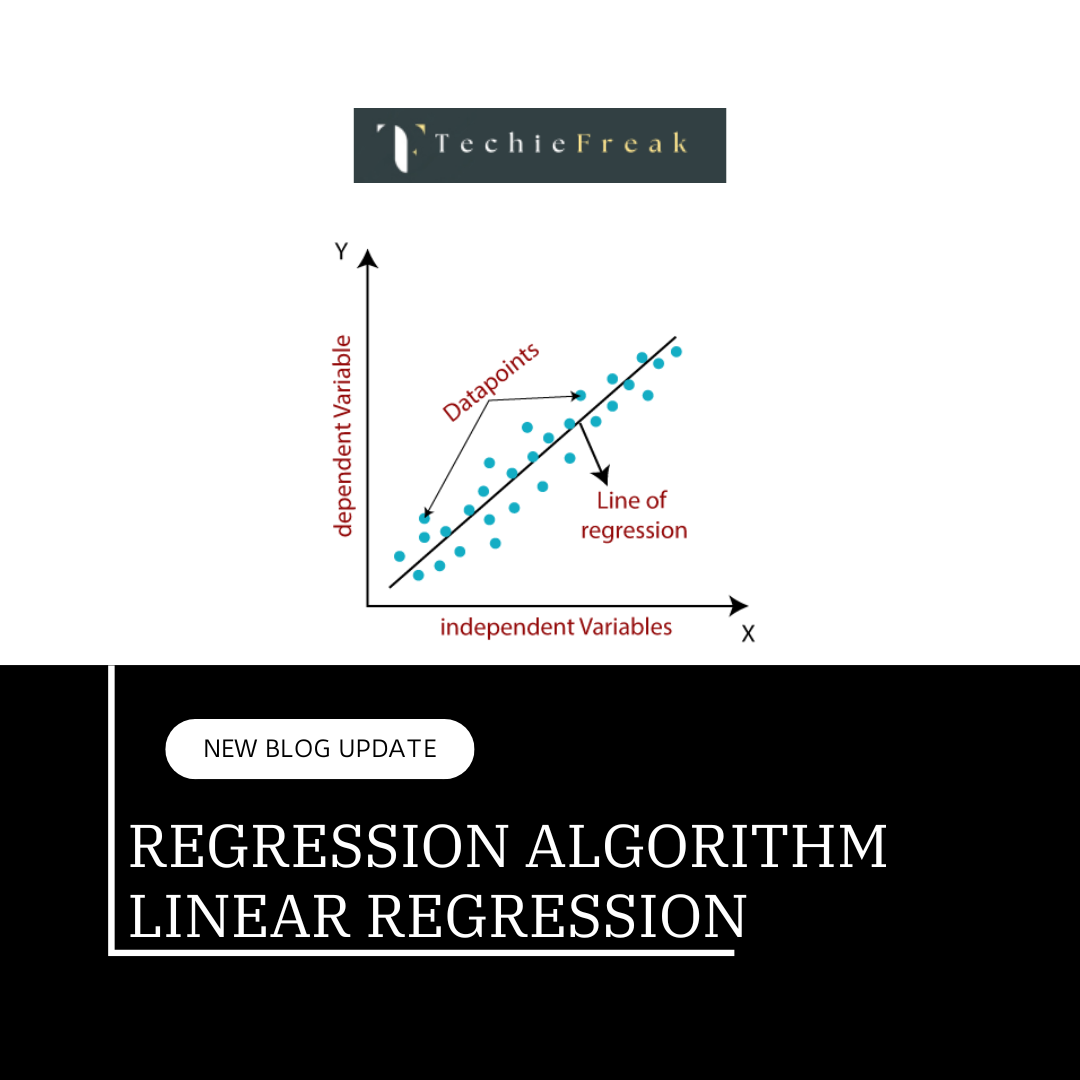
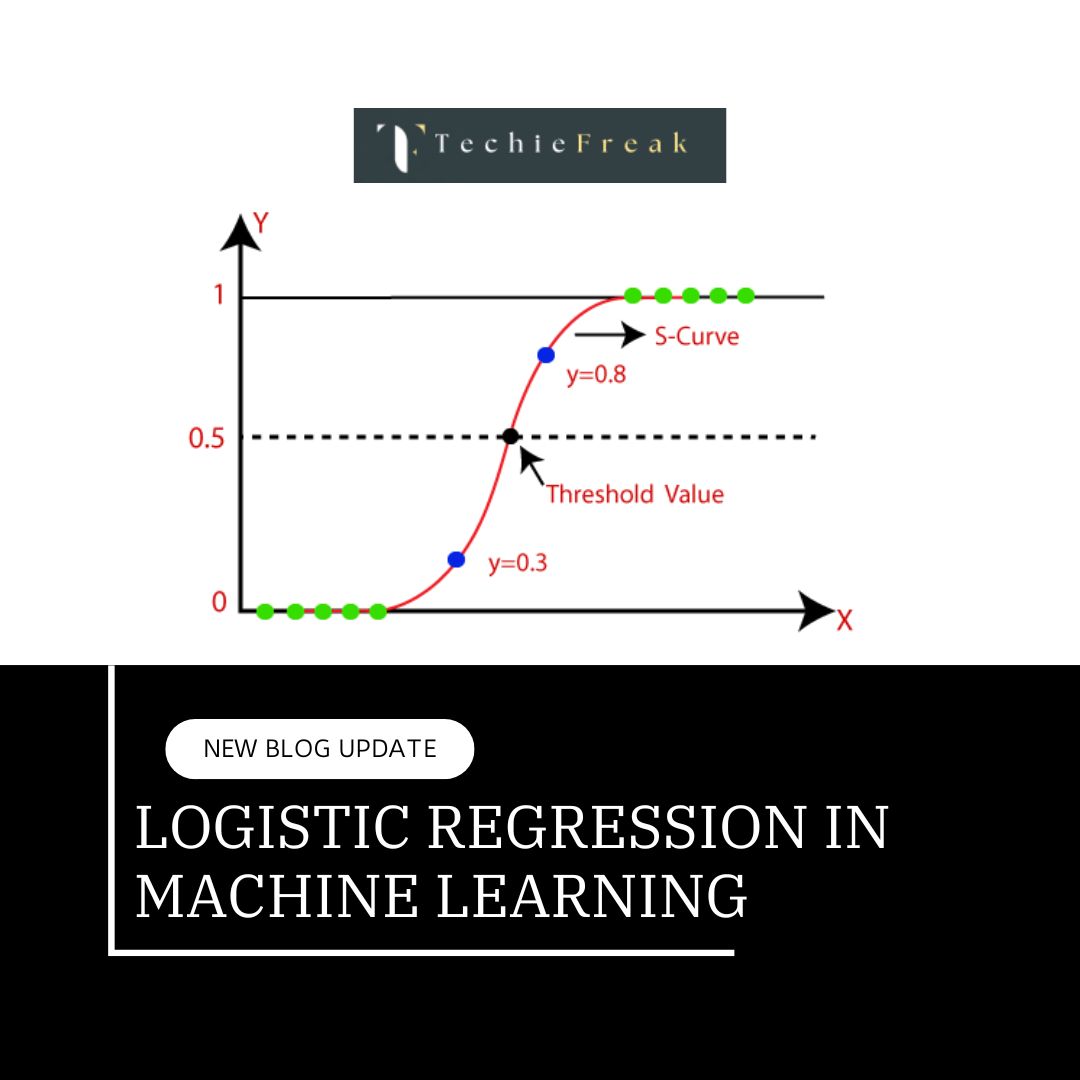
Random Forest is a supervised learning algorithm that constructs multiple decision trees and aggregates their results to make final predictions. It is highly effective for both classification and regression problems, providing a reliable and flexible approach to data modeling. By averaging the outputs from multiple trees, Random Forest reduces the risk of overfitting and improves model stability.
How Does It Work?
Random Forest follows these key steps:
- Bootstrapping (Data Sampling):
- The algorithm randomly selects multiple subsets of data from the original dataset using replacement (bootstrapping).
- Each subset is then used to train an independent decision tree.
- Decision Tree Construction:
- Each tree is grown by splitting nodes based on a randomly selected subset of features, ensuring diversity among trees.
- A Gini impurity (for classification) or Mean Squared Error (for regression) criterion is used to determine the best split.
- Aggregation of Predictions:
- For classification, a majority voting system is used where the most frequent class label is chosen.
- For regression, the final prediction is the average of the outputs from all individual trees.
- Final Prediction:
- The ensemble of trees provides a stable and generalized prediction, reducing the likelihood of overfitting compared to a single decision tree.
Advantages of Random Forest
- High Accuracy: Random Forest reduces variance by combining multiple trees, leading to improved predictive accuracy.
- Reduces Overfitting: Unlike a single decision tree, Random Forest generalizes better and prevents overfitting.
- Handles Missing Data: The algorithm maintains accuracy even if there are missing values in the dataset.
- Works Well with Large Datasets: It is well-suited for high-dimensional data and complex problems.
- Feature Importance Ranking: It helps in identifying the most relevant features contributing to predictions.
- Robust to Noise: Since multiple trees contribute to the decision, it is less sensitive to noisy data.
Disadvantages of Random Forest
- Computational Complexity: Training multiple trees requires significant memory and computational power, making it slower compared to a single decision tree.
- Less Interpretability: Unlike individual decision trees, it is challenging to interpret the results of a Random Forest model.
- Slower Predictions: Due to the involvement of multiple trees, the prediction process can be slower than simpler models.
- Bias in Highly Imbalanced Data: If the dataset is highly imbalanced, Random Forest might still lean towards the majority class unless handled carefully.
Pruning in Random Forest
Pruning is a technique used to improve model performance by reducing overfitting. In Random Forest, individual trees are not explicitly pruned like in a single decision tree, but pruning-like effects can be achieved through hyperparameter tuning:
- Max Depth (max_depth): Restricts the depth of each tree, preventing it from growing excessively and overfitting.
- Minimum Samples per Split (min_samples_split): Ensures that nodes are only split when a sufficient number of samples exist, reducing unnecessary splits.
- Minimum Samples per Leaf (min_samples_leaf): Helps maintain a minimum sample size in leaf nodes, preventing overly complex trees.
- Max Features (max_features): Controls the number of features considered for each split, encouraging diversity among trees and reducing overfitting.
If pruning were applied in a Random Forest model, it would typically involve:
- Pre-pruning (early stopping): Restricting tree growth by setting a maximum depth or a minimum number of samples required per leaf.
- Post-pruning: Trimming unnecessary branches after the tree is fully grown (rarely used in Random Forest).
Hyperparameter Tuning in Random Forest
To optimize Random Forest performance, the following hyperparameters can be tuned:
1. Number of Trees (n_estimators)
Defines the number of trees in the forest. A higher number improves accuracy but increases computational cost. A common range is between 100 to 500 trees, but the optimal number depends on the dataset size and complexity.
2. Maximum Depth (max_depth)
Controls how deep each decision tree can grow. Deeper trees capture more complexity but may lead to overfitting. A depth between 10 to 30 is commonly used, but tuning is required based on the dataset.
3. Minimum Samples per Split (min_samples_split)
Defines the minimum number of samples required to split an internal node. Higher values prevent overfitting but might reduce model flexibility. A typical value is between 2 to 10.
4. Minimum Samples per Leaf (min_samples_leaf)
Ensures each leaf node contains at least a certain number of samples. This helps prevent the model from learning noise and reduces overfitting. Recommended values are 1 to 5 for small datasets and higher for larger datasets.
5. Maximum Features (max_features)
Determines the number of features considered for each split. Selecting too many features increases computational cost, while too few might reduce model accuracy. Common options:
- sqrt (default for classification)
- log2
- A fixed number of features
6. Bootstrap (bootstrap)
Controls whether bootstrapping is used while building trees. Setting bootstrap=True (default) ensures that trees are trained on different subsets of data, improving model generalization.
7. Criterion (criterion)
Defines the function used to measure the quality of a split. Options include:
- For classification: gini (default) or entropy
- For regression: mse (Mean Squared Error), mae (Mean Absolute Error)
Real-World Applications
1. Fraud Detection
- Used in financial institutions to detect fraudulent transactions by identifying anomalies in user behavior.
2. Medical Diagnosis
- Helps in predicting diseases such as cancer by analyzing patient data.
3. Customer Churn Prediction
- Businesses use it to identify customers who are likely to stop using their services.
4. Stock Market Prediction
- Helps in analyzing historical data and predicting stock price movements.
5. Natural Language Processing (NLP)
- Applied in sentiment analysis, spam detection, and text classification tasks.
6. Image Classification
- Used in facial recognition systems and medical imaging to classify objects and patterns.
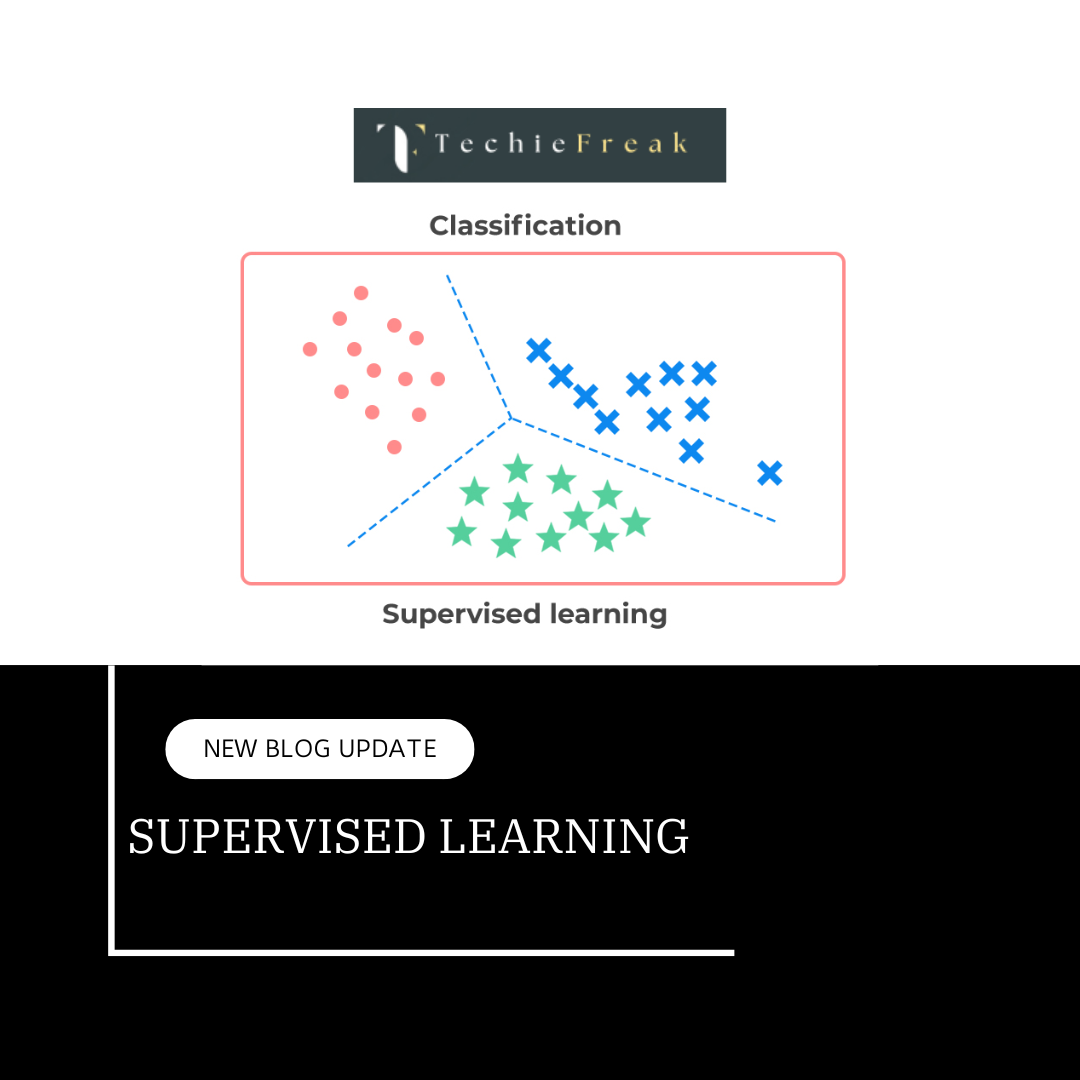
Supervised Learning and Its Applications
Random Forest falls under supervised learning, where models learn from labeled datasets to make predictions. Supervised learning is widely used in:
- Fraud Detection: Identifying fraudulent transactions in financial institutions.
- Medical Diagnosis: Predicting diseases such as cancer-based on patient data.
- Customer Churn Prediction: Identifying customers likely to stop using services.
- Stock Market Prediction: Analyzing historical data to forecast stock price movements.
- Natural Language Processing (NLP): Sentiment analysis, spam detection, and text classification.
- Image Classification: Used in facial recognition and medical imaging for pattern recognition.
Why Random Forest Gives More Accurate Results
Random Forest is often preferred over other machine learning models due to its:
- Reduced Overfitting: Unlike a single decision tree, Random Forest generalizes well across unseen data by averaging predictions.
- Ensemble Learning: Combining multiple trees leads to better stability and reliability.
- Robustness to Noisy Data: The impact of individual outliers is minimized.
- Automatic Feature Selection: Random Forest identifies important features, reducing reliance on irrelevant data.
- Versatility: Works well for both classification and regression tasks across diverse domains.
Key Takeaways: Random Forest Algorithm
- Definition: Random Forest is an ensemble learning method that builds multiple decision trees and aggregates their results for better accuracy and stability.
- Working Mechanism: Uses bootstrapping (data sampling), decision tree construction with feature selection, and aggregation (majority voting for classification, averaging for regression).
- Advantages:
- High accuracy and robustness
- Reduces overfitting compared to single decision trees
- Handles missing data well
- Works efficiently on large datasets
- Provides feature importance ranking
- Disadvantages:
- Computationally expensive
- Less interpretable than individual decision trees
- Slower predictions due to multiple trees
- May struggle with highly imbalanced datasets
- Pruning in Random Forest: Controlled using hyperparameters like max_depth, min_samples_split, min_samples_leaf, and max_features to prevent overfitting.
- Hyperparameter Tuning: Key parameters include n_estimators, max_depth, min_samples_split, min_samples_leaf, max_features, bootstrap, and criterion.
- Real-World Applications: Used in fraud detection, medical diagnosis, customer churn prediction, stock market analysis, NLP, and image classification.
- Why It’s Accurate: Reduces overfitting, benefits from ensemble learning, handles noisy data well, and automatically selects important features.
Next Blog- Step-wise Python Implementation of Random Forests

.png)
.png)
.png)

.png)
.png)
.png)
 Algorithm for Machine Learning.jpg)
 Algorithm.jpg)

.png)
.png)
.png)
.png)
.png)