.png)
Step-wise Python Implementation of Random Forests
Random Forest is an ensemble learning method that combines multiple decision trees to improve accuracy and prevent overfitting. It can be used for both classification and regression tasks.
Steps for Implementing Random Forest in Python
Step 1: Import Required Libraries
Before implementing Random Forest, import the necessary Python libraries.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestClassifier, RandomForestRegressor
from sklearn.metrics import accuracy_score, confusion_matrix, classification_report
Step 2: Load and Explore the Dataset
In this step we will read the data some of the open repositories like Kaggle dataset, UCI Machine Learning Repository etc and explore the data to understand the features and its importance.
We will use the Iris dataset as an example for classification.
from sklearn.datasets import load_iris
# Load dataset
iris = load_iris()
df = pd.DataFrame(iris.data, columns=iris.feature_names)
df['target'] = iris.target
# Display first 5 rows
print(df.head())
Ouput:
sepal length (cm) sepal width (cm) petal length (cm) petal width (cm) \
0 5.1 3.5 1.4 0.2
1 4.9 3.0 1.4 0.2
2 4.7 3.2 1.3 0.2
3 4.6 3.1 1.5 0.2
4 5.0 3.6 1.4 0.2
target
0 0
1 0
2 0
3 0
4 0
Step 3: Split the Data into Training and Testing Sets
In this step we will split the dataset into training and testing datasets and also apply the scaling to bring all the features on the same scale.
Splitting data helps evaluate the model’s performance.
# Define features and target variable
X = df.drop(columns=['target'])
y = df['target']
# Split into training and testing sets (80% train, 20% test)
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42)
Step 4: Initialize and Train the Random Forest Model
We will create the instance of RandomForestClassifier for classification and train he model using the training data (X_train, y_train).
# Create a Random Forest Classifier
rf_model = RandomForestClassifier(n_estimators=100, random_state=42)
# Train the model
rf_model.fit(X_train, y_train)
Step 5: Make Predictions
As we have trained the model now time is to test the model using testing data (X_test, y_test)
Now, we predict on the test dataset.
# Predict on test data
y_pred = rf_model.predict(X_test)
print(y_pred)
Output:
[1 0 2 1 1 0 1 2 1 1 2 0 0 0 0 1 2 1 1 2 0 2 0 2 2 2 2 2 0 0]
Step 6: Evaluate the Model
We assess the model's performance using accuracy and a confusion matrix.
# Accuracy Score
accuracy = accuracy_score(y_test, y_pred)
print(f'Accuracy: {accuracy:.2f}')
# Confusion Matrix
conf_matrix = confusion_matrix(y_test, y_pred)
print("Confusion Matrix:\n", conf_matrix)
# Classification Report
print("Classification Report:\n", classification_report(y_test, y_pred))
Output:
Accuracy: 1.00
Confusion Matrix:
[[10 0 0]
[ 0 9 0]
[ 0 0 11]]
Classification Report:
precision recall f1-score support
0 1.00 1.00 1.00 10
1 1.00 1.00 1.00 9
2 1.00 1.00 1.00 11
accuracy 1.00 30
macro avg 1.00 1.00 1.00 30
weighted avg 1.00 1.00 1.00 30
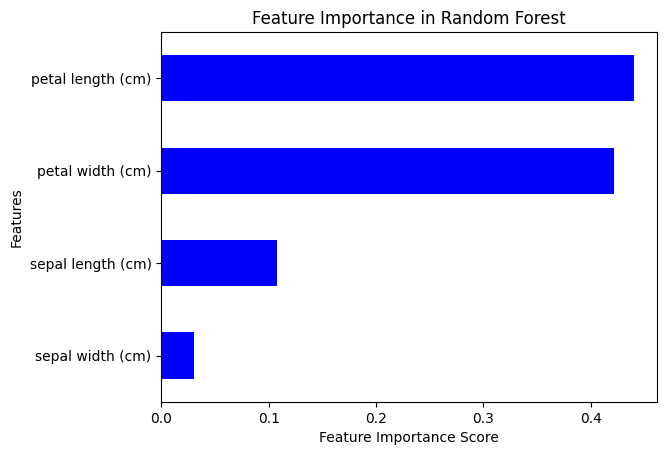
Step 7: Feature Importance
Random Forest provides a way to measure feature importance.
# Plot feature importance
feature_importances = pd.Series(rf_model.feature_importances_, index=X.columns)
feature_importances.sort_values(ascending=True).plot(kind='barh', color='blue')
plt.xlabel('Feature Importance Score')
plt.ylabel('Features')
plt.title('Feature Importance in Random Forest')
plt.show()
Hyperparameter Tuning in Random Forest
We can improve model performance by tuning hyperparameters using GridSearchCV.
from sklearn.model_selection import GridSearchCV
# Define parameter grid
param_grid = {
'n_estimators': [50, 100, 150],
'max_depth': [None, 10, 20],
'min_samples_split': [2, 5, 10]
}
# Initialize GridSearchCV
grid_search = GridSearchCV(RandomForestClassifier(random_state=42), param_grid, cv=5, n_jobs=-1)
grid_search.fit(X_train, y_train)
# Best parameters
print("Best Parameters:", grid_search.best_params_)
# Evaluate best model
best_rf = grid_search.best_estimator_
y_pred_best = best_rf.predict(X_test)
print("Best Model Accuracy:", accuracy_score(y_test, y_pred_best))
OUTPUT:
Best Parameters: {'max_depth': None, 'min_samples_split': 2, 'n_estimators': 150}
Best Model Accuracy: 1.0
Key Takeaway:
This guide covers the step-wise implementation of Random Forest for classification and regression. We also explored feature importance and hyperparameter tuning. Random Forest is a powerful technique that provides accurate results while reducing overfitting.
Next Blog- Python Implementation of Random Forest for Regression

.png)
.png)
.png)

.png)
.png)
.png)
 Algorithm for Machine Learning.jpg)
 Algorithm.jpg)

.png)
.png)
.png)
.png)
.png)