.png)
Generative Adversarial Networks (GANs)
Introduction
Generative Adversarial Networks (GANs) are a class of deep learning models designed for generating new data that resembles real-world data. They have gained immense popularity in applications such as image generation, style transfer, deepfake creation, and text-to-image synthesis.
GANs consist of two neural networks that compete against each other:
- Generator (G) – Creates new, synthetic data.
- Discriminator (D) – Evaluates the authenticity of the generated data.
This adversarial process leads to the improvement of both networks, enabling the generator to produce highly realistic outputs.
What are GANs?
GANs were introduced by Ian Goodfellow in 2014 and have since revolutionized the field of generative modeling. They are used to generate synthetic data that mimics real-world data distributions.
For example, GANs can generate:
- Realistic human faces (e.g., deepfake technology)
- Artificial paintings (e.g., AI-generated art)
- Synthetic voice and music (e.g., AI-generated songs)
- Super-resolution images (e.g., enhancing low-resolution images)
The key idea behind GANs is adversarial learning, where two networks—the Generator and the Discriminator—compete against each other in a zero-sum game.
Got it! Here's the revised summary without emojis:
Architecture of Generative Adversarial Networks (GANs)
Generative Adversarial Networks (GANs) are a class of deep learning models introduced by Ian Goodfellow in 2014. They consist of two competing neural networks that work together in a game-theoretic framework to generate realistic data.
1. Components of a GAN
A GAN consists of two key neural networks:
(1) Generator (G) – The Creator
The generator is responsible for creating realistic fake data from a random noise input.
How It Works:
- Takes random noise (e.g., Gaussian or uniform noise).
- Passes it through a deep neural network (often a CNN for image generation).
- Produces an output (e.g., an image) that resembles real data.
- The goal of the generator is to fool the discriminator into believing that its output is real.
Mathematical Representation:
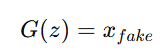
Where:
- G is the generator network.
- z is random noise drawn from a probability distribution pz(z)p_z(z).
- xfake is the generated sample.
(2) Discriminator (D) – The Judge
The discriminator is a classifier that distinguishes between real and fake data.
How It Works:
- Takes input data (either real from the dataset or fake from the generator).
- Uses a deep neural network to analyze the input.
- Outputs a probability (D(x)) indicating whether the data is real (close to 1) or fake (close to 0).
- The goal of the discriminator is to correctly classify real vs. generated data.
Mathematical Representation:
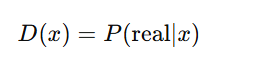
Where:
- D(x) represents the probability that input xx is real.
2. The GAN Training Process: A Min-Max Game
Both networks compete against each other in a zero-sum game:
- The generator tries to fool the discriminator.
- The discriminator tries to correctly classify real and fake data.
This creates an adversarial learning process that improves both networks over time.
Loss Functions:
Discriminator Loss (LD) – Measures how well the discriminator distinguishes between real and fake data:

Where:
- pdata(x) is the real data distribution.
- pz(z) is the noise distribution used by the generator.
Generator Loss (LG) – Measures how well the generator fools the discriminator:
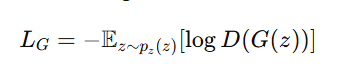
- The generator updates its weights to make D(G(z)) closer to 1.
Minimax Optimization:
The overall objective function is:
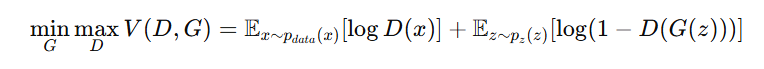
The discriminator maximizes V(D, G) (better classification), while the generator minimizes V(D, G) (better fake samples).
Training Process of GANs
Step 1: Initialize Generator and Discriminator
- The Generator (G) is initialized with random weights.
- The Discriminator (D) is initialized and trained using real data.
Step 2: Train Discriminator (D)
- Feed real data to DD, and it learns to classify it as real.
- Generate fake data using GG and pass it to DD.
- Compute loss (error in classification).
- Update weights of DD using backpropagation.
Step 3: Train Generator (G)
- Generate fake samples and pass them to DD.
- Calculate loss based on how well GG fooled DD.
- Update weights of GG to improve fake sample quality.
Step 4: Repeat the Process
- The generator gets better at fooling the discriminator.
- The discriminator gets better at detecting fakes.
- Eventually, the generator produces highly realistic samples.
| Component | Role |
|---|---|
| Generator (G) | Generates fake data from random noise. |
| Discriminator (D) | Classifies data as real or fake. |
| Loss Function | Minimax game where G tries to fool D, and D tries to detect fakes. |
| Training Goal | Improve both networks until fake data is indistinguishable from real data. |
Types of Generative Adversarial Networks (GANs)
GANs have evolved into various types to address challenges like stability, mode collapse, and training inefficiencies. Below are the major types of GANs and their characteristics:
1. Vanilla GAN (Standard GAN)
Introduced by: Ian Goodfellow (2014)
A generative model where a generator creates fake data and a discriminator classifies real vs. fake data, trained using a minimax game.
How It Works:
- The generator (G) takes random noise and generates data.
- The discriminator (D) distinguishes real from fake data.
- Both networks are trained in a minimax game using the standard loss function.
Limitations:
- Training instability.
- Mode collapse (generator produces limited variations).
2. Deep Convolutional GAN (DCGAN)
Introduced by: Radford et al. (2015)
A GAN variant that uses convolutional layers, batch normalization, and Leaky ReLU activation to improve stability and image quality.
How It Works:
- Uses convolutional layers instead of fully connected layers for better feature extraction.
- Employs batch normalization to stabilize training.
- Uses Leaky ReLU activation for better gradient flow.
Advantages:
- Generates high-quality images.
- More stable training compared to Vanilla GANs.
Common Applications:
- Image generation (e.g., anime faces, artworks).
3. Conditional GAN (cGAN)
Introduced by: Mirza and Osindero (2014)
A GAN that conditions both the generator and discriminator on extra input (e.g., class labels) to generate category-specific outputs.
How It Works:
- Both G and D receive an additional conditioning variable (e.g., a class label or specific text input).
- The generator learns to generate samples that match a given condition.
Advantages:
- Enables targeted generation (e.g., generating images of specific digits in MNIST).
Common Applications:
- Image-to-image translation.
- Text-to-image generation.
4. Wasserstein GAN (WGAN)
Introduced by: Arjovsky et al. (2017)
Replaces standard loss with Wasserstein distance for better training stability, reducing mode collapse and improving image quality.
How It Works:
- Uses Wasserstein distance instead of cross-entropy loss for better training stability.
- Replaces the discriminator with a "critic" that estimates Wasserstein distance.
- Uses weight clipping or gradient penalty to enforce the Lipschitz constraint.
Advantages:
- Reduces mode collapse.
- Provides stable training.
Common Applications:
- High-quality image generation.
5. Least Squares GAN (LSGAN)
Introduced by: Mao et al. (2017)
Uses least squares loss to penalize fake samples based on their distance from real labels, stabilizing training and generating smoother images.
How It Works:
- Uses least squares loss instead of binary cross-entropy loss.
- Penalizes samples based on how far they are from real or fake labels.
Advantages:
- Stabilizes training.
- Generates high-quality images with smoother gradients.
Common Applications:
- Image enhancement and generation.
6. InfoGAN (Information Maximizing GAN)
Introduced by: Chen et al. (2016)
A variation of GAN that learns disentangled and interpretable latent representations by maximizing mutual information between latent codes and outputs
How It Works:
- Extends cGAN by learning disentangled latent representations.
- Maximizes mutual information between some latent variables and generated outputs.
Advantages:
- Generates interpretable and structured representations.
Common Applications:
- Controlling image attributes (e.g., face expressions, object orientations).
7. Progressive Growing GAN (PGGAN)
Introduced by: Karras et al. (2018)
A GAN that starts with low-resolution images and progressively increases layers, improving high-resolution image generation.
How It Works:
- Starts with a low-resolution image and progressively adds layers to refine details.
- Helps in training high-resolution image generators efficiently.
Advantages:
- Generates ultra-high-resolution images (e.g., 1024x1024 pixels).
Common Applications:
- Deepfake technology.
- High-resolution face generation.
8. StyleGAN
Introduced by: Karras et al. (2019)
A GAN that introduces style-based image synthesis using adaptive instance normalization (AdaIN), allowing fine control over generated features
How It Works:
- Uses style-based generation instead of traditional latent space sampling.
- Modifies different aspects of an image separately (e.g., face shape, hair color).
- Introduces adaptive instance normalization (AdaIN) to control styles.
Advantages:
- High-quality and controllable image generation.
Common Applications:
- AI-generated faces (ThisPersonDoesNotExist.com).
- Customizable avatar creation.
9. CycleGAN
Introduced by: Zhu et al. (2017)
A GAN that enables unpaired image-to-image translation by using cycle consistency loss to learn mappings between two domains.
How It Works:
- Performs unpaired image-to-image translation (e.g., turning horse images into zebra images).
- Uses cycle consistency loss to ensure one-to-one mapping between domains.
Advantages:
- Works without paired datasets.
Common Applications:
- Artistic style transfer (e.g., converting photos into Van Gogh paintings).
- Domain adaptation (e.g., day-to-night image transformation).
10. Pix2Pix
Introduced by: Isola et al. (2017)
A supervised GAN that learns mappings between paired images for tasks like translating sketches to realistic images or grayscale to color conversion.
How It Works:
- A conditional GAN that requires paired data for image-to-image translation.
- Uses U-Net as a generator and PatchGAN as a discriminator.
Advantages:
- Produces high-quality results for paired datasets.
Common Applications:
- Satellite-to-map image conversion.
- Black-and-white to color image transformation.
Comparison of Different GANs
| GAN Type | Key Feature | Common Application |
|---|---|---|
| Vanilla GAN | Basic GAN structure | General image generation |
| DCGAN | Uses CNNs for stability | Image synthesis |
| cGAN | Uses labels as input | Targeted image generation |
| WGAN | Uses Wasserstein loss | Stable image generation |
| LSGAN | Uses least squares loss | Improved gradient flow |
| InfoGAN | Learns structured latent spaces | Controllable image generation |
| PGGAN | Grows layers progressively | High-resolution images |
| StyleGAN | Generates diverse styles | AI face generation |
| CycleGAN | Unpaired image-to-image translation | Style transfer |
| Pix2Pix | Paired image-to-image translation | Black-and-white to color |
Challenges in Training GANs
GANs are powerful but difficult to train due to several challenges:
1. Mode Collapse
- The generator may produce limited variations instead of diverse samples.
- Example: If generating human faces, it may only produce one type of face repeatedly.
- Solution: Use Wasserstein GAN (WGAN) or Minibatch Discrimination.
2. Vanishing Gradient Problem
- If DD becomes too strong, GG stops learning (gradients vanish).
- Solution: Use techniques like WGAN with Gradient Penalty (WGAN-GP).
3. Unstable Training
- Training may oscillate without convergence.
- Solution: Use Batch Normalization and Progressive Growing of GANs.
4. Evaluation Difficulty
- Unlike classification models, GANs don’t have a clear evaluation metric.
- Solution: Use Fréchet Inception Distance (FID) to measure sample quality.
Applications of GANs
1. Image Generation & Enhancement
- Deepfake Technology – Generating realistic human faces.
- Super-Resolution – Enhancing low-resolution images.
- Style Transfer – Transforming photos into artistic styles.
2. Data Augmentation
- Creating synthetic training data for machine learning models.
3. Video & Animation
- AI-generated movies and animations.
- Frame interpolation for smooth video playback.
4. Text-to-Image Synthesis
- Models like DALL·E use GANs to generate images from text descriptions.
5. Drug Discovery & Medical Imaging
- Generating synthetic medical scans for training deep learning models.
Key Takeaways:
GANs consist of two competing networks: Generator and Discriminator.
They generate realistic images, videos, and text.
Training GANs is challenging due to mode collapse and instability.
Variants like WGAN, StyleGAN, and CycleGAN enhance performance.
Applications range from deepfake generation to medical imaging and AI art.
Next Blog- Python Implementation of Generative Adversarial Network
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)