 (33).png)
Custom Implementation of HashSet in Java
Understanding Internal Working and Step-by-Step Construction
Introduction
HashSet is one of Java’s core Collection classes. It is part of the Java Collections Framework and implements the Set interface. A Set is a collection of unique elements — meaning it does not allow duplicate values.
The interesting part is that internally HashSet uses HashMap for storage. This design decision ensures that HashSet provides constant-time performance for basic operations like add, remove, and contains.
In this blog, we will:
- Understand how HashSet works internally.
- Learn about its relationship with HashMap.
- Build a custom HashSet from scratch.
- Analyze its advantages, disadvantages, and real-world use cases.
Understanding the Relationship Between HashSet and HashMap
A HashSet in Java is essentially backed by a HashMap.
When you add an element to a HashSet, the element is stored as a key in the internal HashMap.
The value is a constant dummy object (a placeholder).
Example:
HashSet set = new HashSet<>();
set.add("Java");
set.add("Python");
set.add("C++");
Internally:
HashMap:
[Java=null, Python=null, C++=null]
This means:
- The uniqueness guarantee in HashSet comes from the uniqueness of HashMap keys.
- HashSet relies entirely on HashMap’s hashing mechanism.
Core Features of HashSet
- Stores unique elements only.
- Allows null values (only one null element allowed).
- Unordered collection — insertion order is not maintained.
- Backed by a HashMap internally.
Designing a Custom HashSet
Since HashSet internally uses HashMap, we will follow a similar approach but keep it simpler.
Step 1: Define a CustomHashSet Class
public class CustomHashSet {
private static final Object DUMMY = new Object();
private CustomHashMap map;
public CustomHashSet() {
map = new CustomHashMap<>();
}
}
Here:
- We use our previously implemented CustomHashMap to store elements.
- A single dummy object is used as the value for all keys.
Step 2: Implement the add() Method
This will add elements to the set.
public boolean add(K key) {
if (map.get(key) == null) {
map.put(key, DUMMY);
return true;
}
return false; // element already exists
}
Step 3: Implement the contains() Method
Checks whether the element exists.
public boolean contains(K key) {
return map.get(key) != null;
}
Step 4: Implement the remove() Method
Removes the element from the set.
public boolean remove(K key) {
return map.remove(key);
}
Step 5: Implement the display() Method
Displays all elements in the set.
public void display() {
map.display();
}
Step 6: Testing the CustomHashSet
public class TestCustomHashSet {
public static void main(String[] args) {
CustomHashSet set = new CustomHashSet<>();
set.add("Java");
set.add("Python");
set.add("C++");
set.add("Java"); // duplicate element
set.display();
System.out.println("Contains Python? " + set.contains("Python"));
System.out.println("Contains Ruby? " + set.contains("Ruby"));
set.remove("Python");
set.display();
}
}
Expected Output
Bucket 1: [Java]
Bucket 2: [Python]
Bucket 3: [C++]
Contains Python? true
Contains Ruby? false
Bucket 1: [Java]
Bucket 3: [C++]
Got it — you only want the CustomHashSet complete implementation (self-contained, no external CustomHashMap dependency).
CustomHashSet – Complete Code
import java.util.LinkedList;
public class CustomHashSet<K> {
// Node class for each element in the set
private class Node {
K key;
Node(K key) {
this.key = key;
}
}
// Default initial capacity
private int capacity = 10;
private LinkedList<Node>[] buckets;
private int size = 0;
@SuppressWarnings("unchecked")
public CustomHashSet() {
buckets = new LinkedList[capacity];
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
}
// Hash function to calculate bucket index
private int hash(K key) {
return Math.abs(key.hashCode() % capacity);
}
// Add element to set
public boolean add(K key) {
int index = hash(key);
LinkedList<Node> bucket = buckets[index];
for (Node node : bucket) {
if (node.key.equals(key)) {
return false; // already exists
}
}
bucket.add(new Node(key));
size++;
// Optional: rehash if load factor exceeds threshold
if ((1.0 * size) / capacity > 0.7) {
rehash();
}
return true;
}
// Check if element exists
public boolean contains(K key) {
int index = hash(key);
LinkedList<Node> bucket = buckets[index];
for (Node node : bucket) {
if (node.key.equals(key)) {
return true;
}
}
return false;
}
// Remove element
public boolean remove(K key) {
int index = hash(key);
LinkedList<Node> bucket = buckets[index];
for (Node node : bucket) {
if (node.key.equals(key)) {
bucket.remove(node);
size--;
return true;
}
}
return false;
}
// Display all elements
public void display() {
for (int i = 0; i < capacity; i++) {
if (!buckets[i].isEmpty()) {
System.out.print("Bucket " + i + ": ");
for (Node node : buckets[i]) {
System.out.print("[" + node.key + "] ");
}
System.out.println();
}
}
}
// Returns number of elements
public int size() {
return size;
}
// Internal method to rehash (resize and redistribute keys)
@SuppressWarnings("unchecked")
private void rehash() {
LinkedList<Node>[] oldBuckets = buckets;
capacity *= 2;
buckets = new LinkedList[capacity];
size = 0;
for (int i = 0; i < capacity; i++) {
buckets[i] = new LinkedList<>();
}
for (LinkedList<Node> bucket : oldBuckets) {
for (Node node : bucket) {
add(node.key);
}
}
}
// Test main method
public static void main(String[] args) {
CustomHashSet<String> set = new CustomHashSet<>();
set.add("Java");
set.add("Python");
set.add("C++");
set.add("Java"); // duplicate
System.out.println("Initial Set:");
set.display();
System.out.println("Contains Python? " + set.contains("Python"));
System.out.println("Contains Ruby? " + set.contains("Ruby"));
set.remove("Python");
System.out.println("\nAfter Removing Python:");
set.display();
}
}
Expected Output
Initial Set:
Bucket 1: [Java]
Bucket 2: [Python]
Bucket 3: [C++]
Contains Python? true
Contains Ruby? false
After Removing Python:
Bucket 1: [Java]
Bucket 3: [C++]
Explanation
- Buckets: Array of linked lists used to store elements based on hash codes.
- Hash Function: Uses hashCode() of the key to determine its bucket index.
- Add: Checks for duplicates, then adds new elements.
- Contains: Returns true if the key exists.
- Remove: Deletes an element if found.
- Rehashing: Automatically doubles bucket size when load factor exceeds 0.7 to maintain efficiency
Internal Working of HashSet
Here’s what happens internally when we perform operations:
- add(element)
- Calls map.put(element, DUMMY)
- HashMap computes the hash index and stores the element as a key.
- contains(element)
- Calls map.get(element)
- Returns true if element exists.
- remove(element)
- Calls map.remove(element)
- Deletes the key from the internal map.
Time Complexity of HashSet Operations
| Operation | Average Case | Worst Case |
|---|---|---|
| add() | O(1) | O(n) |
| contains() | O(1) | O(n) |
| remove() | O(1) | O(n) |
The worst-case scenario happens when all elements hash to the same bucket, forming a linked list (or tree in Java 8+).
Differences Between HashSet and HashMap
| Feature | HashSet | HashMap |
|---|---|---|
| Data Structure | Uses HashMap internally | Uses array of buckets + linked list/tree |
| Storage | Only keys | Key-value pairs |
| Null Values | Allows one null value | Allows one null key and multiple null values |
| Order | Unordered | Unordered |
| Purpose | Store unique elements | Store key-value pairs |
Advantages of HashSet
- Provides O(1) average time complexity for add, remove, and contains.
- Automatically handles uniqueness of elements.
- Easy to implement using HashMap.
- Flexible and widely used in applications.
Disadvantages of HashSet
- No ordering guarantees (use LinkedHashSet for order preservation).
- Not synchronized — requires synchronization for multi-threading (use ConcurrentHashSet).
- Memory overhead because of internal HashMap storage.
- Poor hashCode implementation can degrade performance.
Real-World Applications
- Removing duplicates from a collection.
- Maintaining a list of unique items (e.g., usernames, email IDs).
- Storing distinct elements for mathematical operations.
- Membership checking (fast lookup).
Conclusion
In this blog, we’ve dissected the HashSet implementation and learned that it is basically a wrapper around HashMap.
By building a CustomHashSet, we understood:
- How elements are stored as keys in a HashMap.
- How collisions are handled through hashing and chaining.
- How core set operations map to HashMap operations.
Understanding this relationship not only clarifies HashSet’s internal mechanism but also strengthens your grasp on Java’s Collections Framework.
Next Blog- Custom Implementation of LinkedHashMap in Java
 (17).png)
.png)
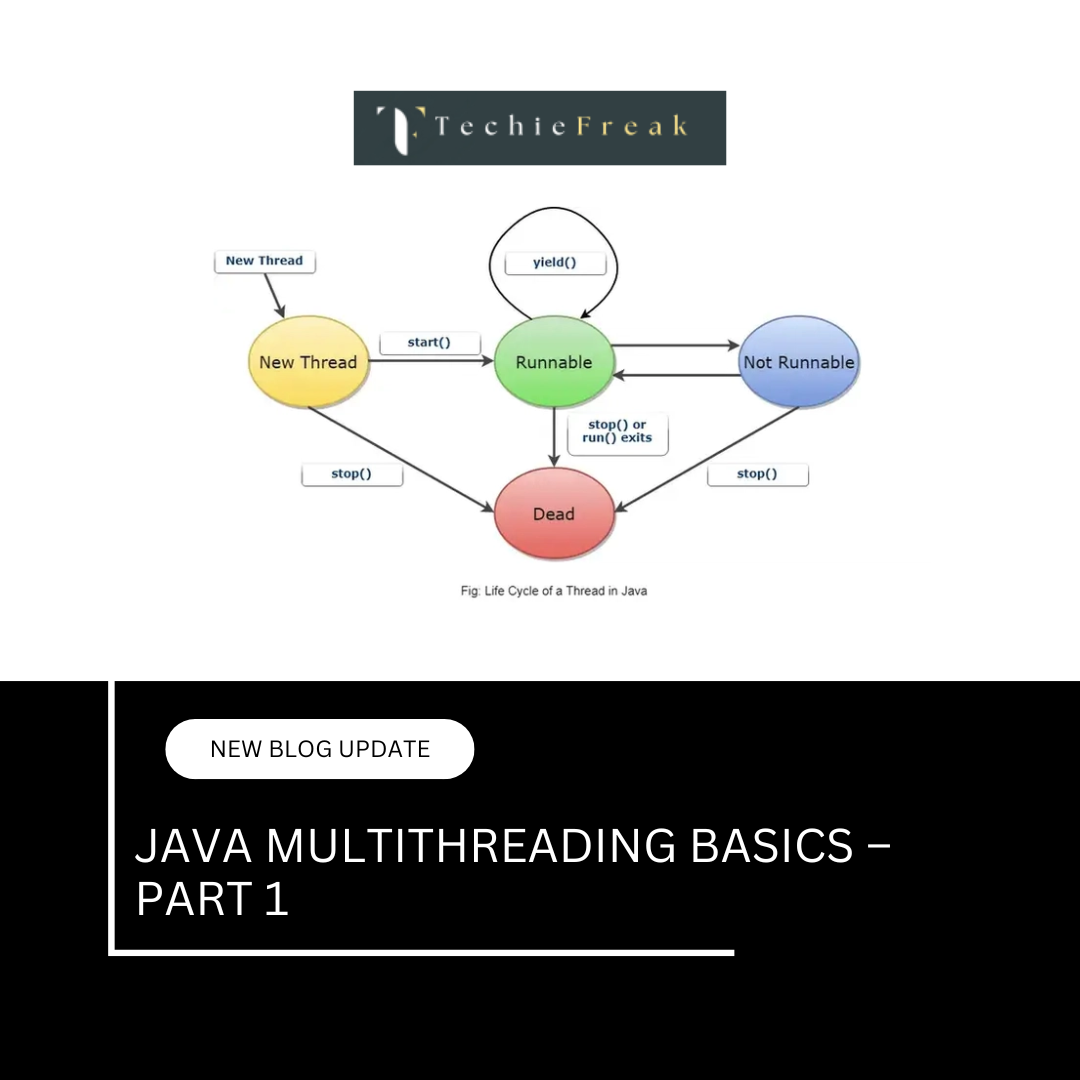
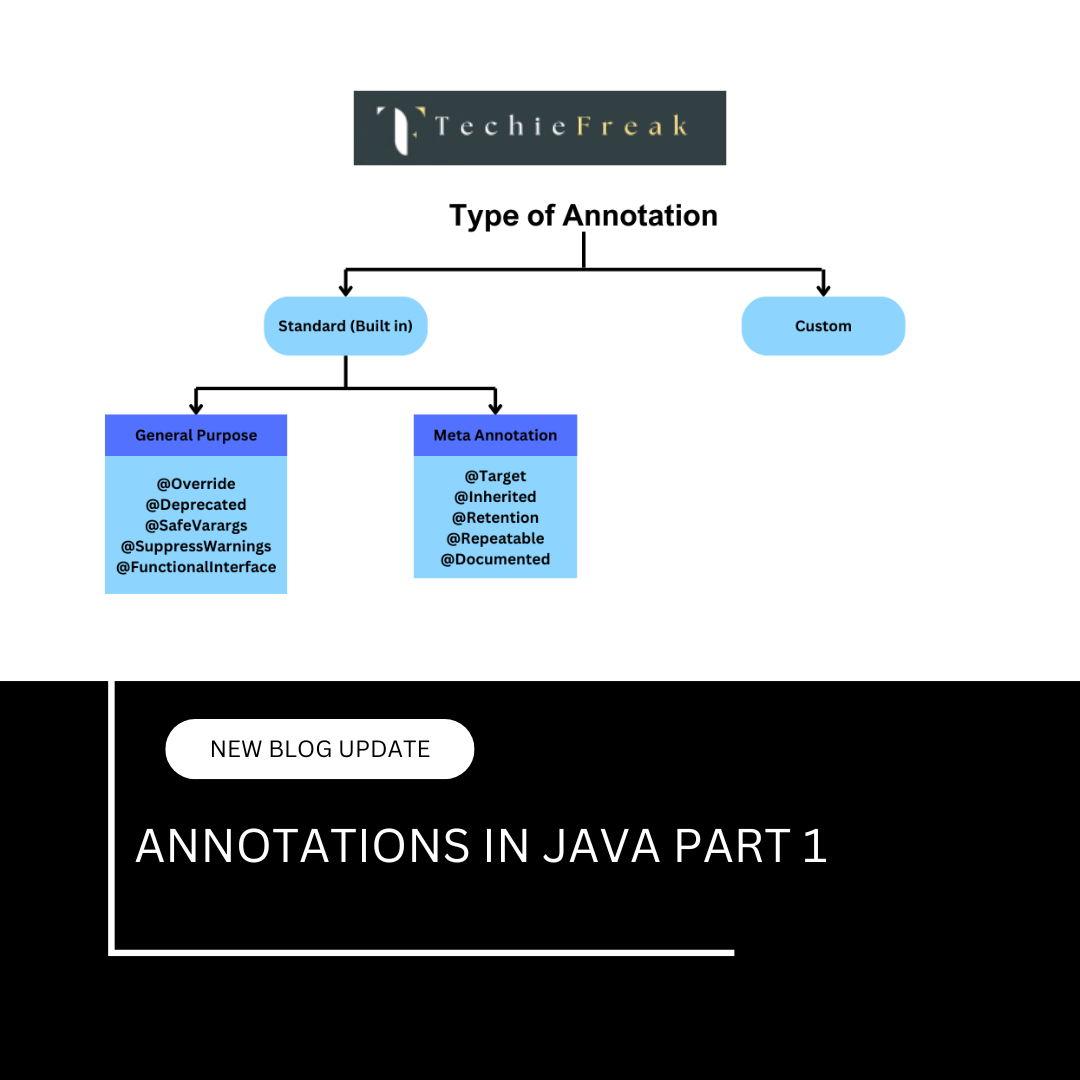
 (18).png)

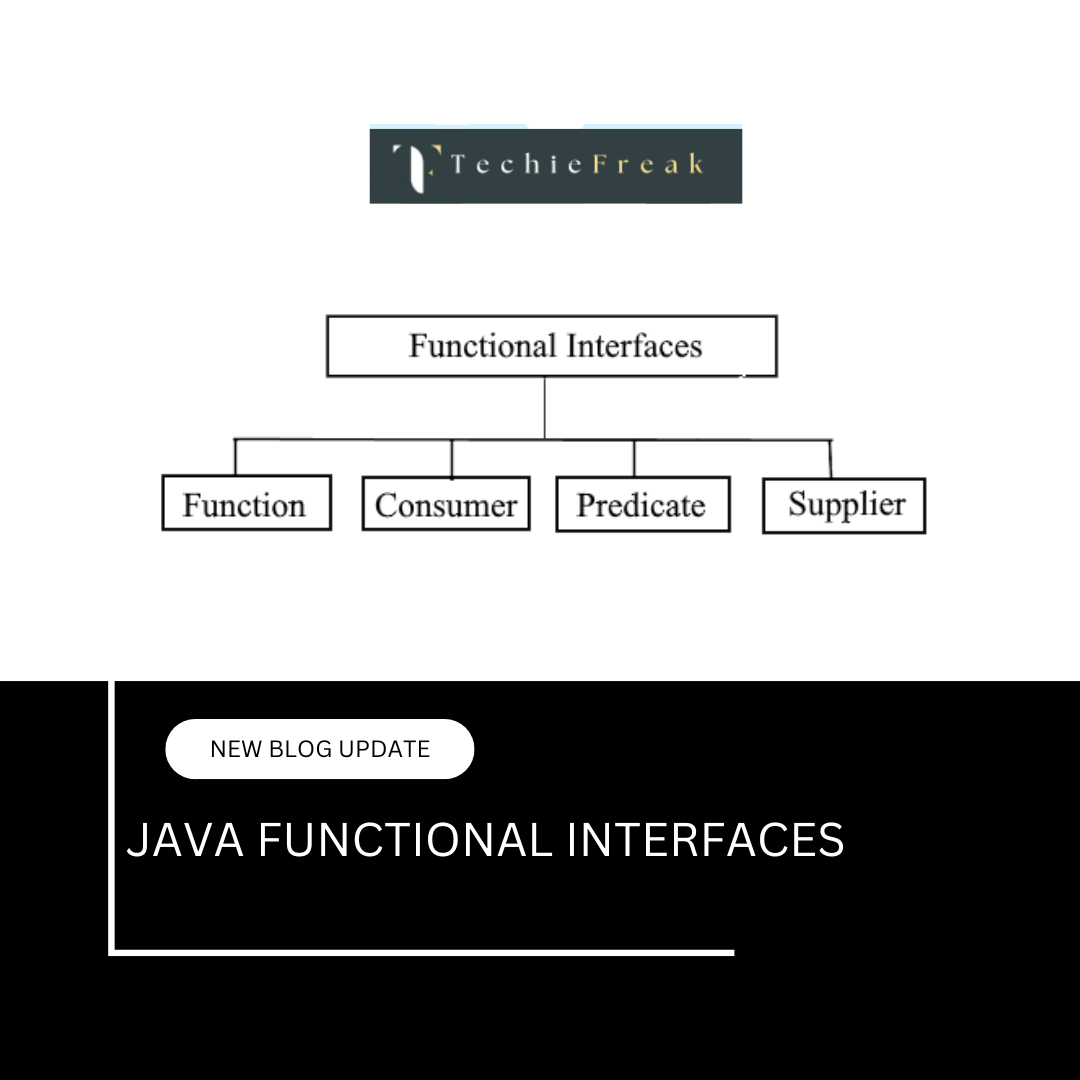
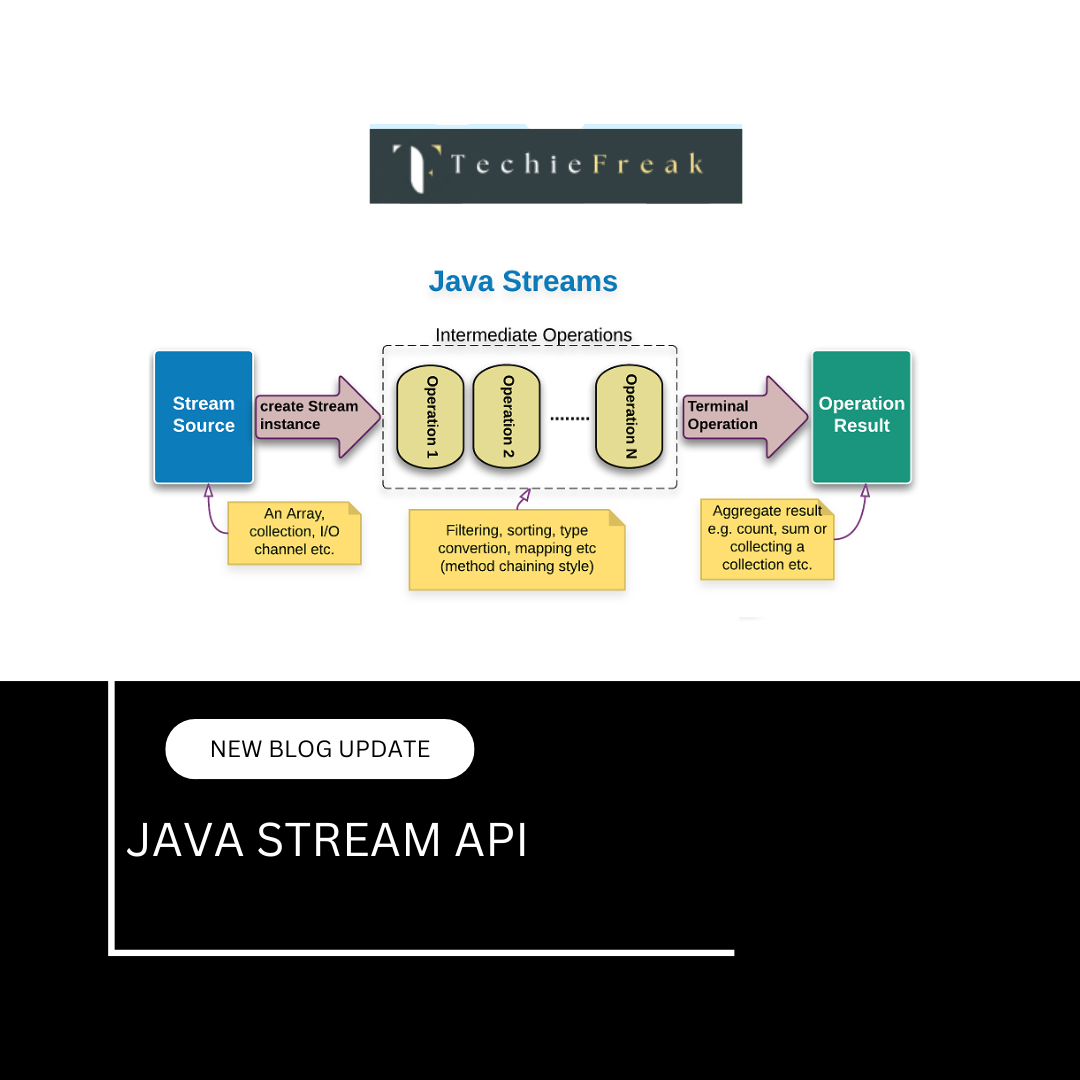
.png)
.png)
 (1).png)
 (2).png)
 (3).png)
 (4).png)
 (5).png)
 (6).png)
 (9).png)
 (7).png)
 (10).png)
 (8).png)
 (10).png)
 (12).png)
 (13).png)
 (13).png)
 (15).png)
 (16).png)
 (19).png)
 (20).png)
 (21).png)
 (22).png)
 (23).png)
 (24).png)
 (25).png)
 (26).png)
 (27).png)
 (28).png)
 (29).png)
 (30).png)
 (31).png)
 (32).png)
 (34).png)
 (35).png)
 (36).png)
 (37).png)
 (38).png)
 (39).png)